
Embedded SRE としてサービスに SRE をやってみた
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
本記事は、横軸組織である SRG がどのように特定のチームへ SRE の文化を形成し、それを継続しているかを簡単にご紹介します。これらを実現するためのビジネスサイドへの説明をした際の資料、文化を形成するための OSS なども紹介しますので SRE の導入の手助けになれば幸です。
この記事の目標⚠ SRE を導入する前にToil などを探すコミュニケーションインシデント対応フローの確立1. ビジネスサイドへサービス品質の話し合いを行うサービス側へ説明した際の資料2. クリティカルユーザージャーニー(CUJ) を決める3. CUJ から SLI を決めるSLI はどこのメトリクスを参照するか4. SLO クエリを書いていく5. Target SLO/Window とエラーバジェットTarget Window について6. エラーバジェットがなくなったら7. SRE を浸透させる、定例などサービス全体に SRE を浸透させるTipsSLO に対するアラートはどうしたらいかエラーバジェットバーンレート終わりに
この記事の目標
横軸組織の SRG がEmbedded SRE (Site Reliability Enginner)としてドットマネーというサービスに参加し、SRE 文化の構築やサービス品質の向上を行うまでにやってきたことをご紹介します。
この記事ではあくまで個人的なやり方であり、多くのパターンで当てはまるやり方ではないかもしれません。そのため、こういうやり方もアリだなと思っていただけると幸いです。
⚠ SRE を導入する前に
Embedded SRE として参加したら、いきなり SRE の話をするのではなくサービス側の部署から自身への信頼性を獲得するために色々なことを行いました。
これは私自身 SRE が初めてだったこと、そしてサービス側が SRE のメリットを享受する前に疲れてしまう可能性があるため、先に自身の信頼性を獲得しておくことで、これをいくらか軽減するのが目的です。
私がまずやってきたのは Toil の削減と、コミュニケーションです。
Toil などを探す
サービスのインフラ構成を把握したり、デプロイフローなどを調査しているうちに Toil が見つかりました。
例えば、
- 全くメンテナンスされていない EC2 と IaC
- 過剰なリソース割当によるコストの無駄
- 長時間かかるデプロイフロー
- インシデント発生時の対応フローがない
などなど
この記事の目的は SRE なので詳細は省きますが、EC2 と Ansible、過剰なリソース割当によるコストの無駄、デプロイフローの改善は全て、EC2 から Fargate へ移行を行うことでサービス側へ数値として明確な成果を示すことができました。
コミュニケーション
ドットマネーでは毎日サーバーサイドの夕会や、週に1回の全体会議などがあるのでそこへ顔を出したり、IaC に対する PR への積極的なレビュー、(当たり前ですが)インシデントの対応など
インシデント対応フローの確立
サービス品質を担保するためにもインシデント対応フローを確立し MTTR(Mean Time To Repair: 平均修復時間)を短縮することも SRE の1つです。
そしてその文化を継続させなければなりません。
インシデント対応フローのドキュメントは古くそれに沿ったフローでは動いていなかったためビジネスフローも含めゼロからを確立しました。
ここでは、オンコールの導入、インシデント対応フローの確立、Datadog Incident を活用した MTTR の計測とポストモーテムの運用に関する物事を進めてきました。
1. ビジネスサイドへサービス品質の話し合いを行う
サービス品質を維持するためにビジネスサイドの協力なしに実現することは不可能です。
特にエラーバジェットが枯渇したあとの動き方はプロダクトマネージャーの許可なしに行うことは難しいでしょう。
サービス側へ説明した際の資料
サービス側のエンジニア・ビジネスを含めた全体的なミーティングで、SRE について説明を行った際の資料です。
ここで全てを理解してもらうのは難しいと思います。多くの人が SRE について資料を読んだときに数十分で理解できた人はなかなかいないと思います。
このミーティングでは SRE の概念(SRE を導入することでサービス品質を可視化し、事業判断の材料ができる)を伝えられることをゴールとしました。
2. クリティカルユーザージャーニー(CUJ) を決める
大まかに SRE を知ってもらったあと、ビジネスインパクトがもっとも大きい部分から CUJ を決定します。
なお、いきなりたくさんの CUJ を定義せずにまずは1つの CUJ を決めました。
ドットマネーではポイント交換サイトであるためもっともビジネス影響が大きいのは
ユーザーがサイトに訪れる → 商品ページ一覧を開ける → 交換ができる
という一連の流れを CUJ と定義しました。
3. CUJ から SLI を決める
CUJ を決めたあとはそこから SLO の指標となる SLI を探します。
ここも中々難しいところです。
SLI はどこのメトリクスを参照するか
ドットマネーでは Realtime User Monitoring(RUM)を導入していないためフロントからのメトリクスは利用せず、ユーザーからもっとも近いロードバランサーのログを利用しています。
逆にフロントからのメトリクスを利用するとユーザーのネットワーク環境などに左右され、外れ値などを除外していく作業が大変、かつ RUM はどこも💰がかかるので最初に SRE を導入するのであればユーザーからもっとも近いロードバランサーのメトリクス、ログを利用するのが簡単だと思います。
理想を語ればフロントで正しいデータを使えればロードバランサーなどのメトリクスなどよりも信憑性が高いものになります。これはフロント側の実装によるサービス品質の変化にも追従できるためです。
Google SRE の Cindy Quach さんが公開している記事、Learn how to set SLOs でも、フロントでの計測はせず LB(Istio) での例をあげています。
そして Google Cloud アーキテクチャセンターの記事ではどこから SLI を計測するかについて詳細に記載されています。
この記事でもクライアント側での計測では変動が大きい要素が多くレスポンスに関するトリガーには適していないと記載されています。
いろんな意味で労力さえあればフロント(クライアント)での計測はもちろん可能ですが今回は、はじめて SRE をやるので手軽なユーザーからもっとも近いロードバランサーで計測するようにしました。
4. SLO クエリを書いていく
今回のCUJ(ユーザーがサイトに訪れる → 商品ページ一覧を開ける → 交換ができる)はすべて「3秒以内に正常にレスポンスが返せる」としています。
なぜ3秒?
SLO を決める前のレスポンスタイムを調査し、現状達成できそうないい感じの値が3秒でした。
弊社の別サービスでは実際に API レスポンスにわざと遅延を設け、どれぐらいでユーザー体験が損なわれるかを体感で設定していたりします。
ドットマネーで現在利用している「ユーザーがトップページに訪れる」際の Datadog クエリを例にあげます。
ドットマネーでは頻繁に DoS 攻撃を受けるため、DoS に関するリクエストや、怪しいリクエストを除外しています。
怪しいユーザーエージェントなどは日頃変わっていくので実際はサービス品質に影響がないのに、SLO の値だけどんどん悪くなっていきます。そのため、定期的に見直しなどが必要になります。
正常とはステータスコードとして
の部分です。
4xx は Total Event に含まないようにします。
クエリの部分でミスると SLO に大きな影響を与えるので期待している SLI と相違がないことを複数人で確認できるといいかもしれません。
私はクエリを書いていて数日後にミスしていたことがありました…。
5. Target SLO/Window とエラーバジェット
前項のクエリで実際に現在の SLO を算出してみると 99.5% 程度あることが分かりました。
そのため一旦 Target SLO は全て 99.5% に設定してみました。
Target SLO は柔軟に下げることも、上げることもできます。
最初適当な値を設定し、定例などで見直すことが大事です。
このとき、エラーバジェットが消費されていない状態はあまり良くないことに注意してください。

上記の画像を見ると「交換完了」の SLO モニターのエラーバジェットが全く消費されていないことに気づきます。
一見、エラーバジェットが消費されていないことが称賛されるかもしれませんが言い換えると
「デプロイ回数が少ないのか」「技術的挑戦を行ってないのか」と見方を変えることできます。
エラーバジェットは Target SLO に対して割り当てられた「技術的挑戦」への予算です。
エラーバジェットが余っている状態は Target を厳しくするなどして Target Window に対してちょうど 0% になるようにしましょう。またはデプロイ回数を増やして技術的挑戦を行っていきましょう。
Target Window について
Target Window は定例の頻度や、開発サイクルによって決定します。
ドットマネー自体のデプロイ周期は1週間に約1回ですが、ドットマネーに Embeded SRE として参加しているのは私一人のためリソース的に Target Window は30日が良いと判断しました。
例えばサービスのデプロイが毎週水曜日であれば、SLO に関する定例は木曜日に設定し Target Window を1週間にすることで機能リリースによる SLO の変化やエラーバジェットについて話し合いをすることができます。
次項で説明するエラーバジェットがなくなった際の動き方を考えると Target Window を1週間に設定するのは結構厳しいものがあるんじゃないかなと思ってます。
6. エラーバジェットがなくなったら
ビジネスサイドの同意のもと、ドットマネーではエラーバジェットがなくなった際の動き方を
「本番障害への対応、信頼性回復のための改修、外部会社が関係する機能のリリースを除く場合、エラーバジェットが枯渇した際には機能のリリースを禁止する」
としました。

ドットマネーは外部会社との兼ね合い上、どうしてもリリースしないといけない局面があるためそれを例外としています。
また、機能のリリースを禁止する場合は信頼性回復のための改修ができるリソースがある場合にも例外としています。
こうすることで機能リリースは遅くなりますが、できなくなることはなくなります。
実際、エラーバジェットが枯渇時したときに機能リリース間近でしたが信頼性回復のためにドットマネーのエンジニア1人のリソースを確保していただき、私を含め2人で信頼性回復のための改修に動きつつ、新機能のリリースを並行して行えたため、このエラーバジェット枯渇時の動き方は中々良かったんではないかと思っています。
7. SRE を浸透させる、定例など
SRE は終わりのない文化です。
SRE を導入したら定例などで振り返りや、サービス内に SRE を浸透していく必要があります。
定例ではエラーバジェットの確認だけでなく、SLI が正しいか、SLO は緩すぎないか、キツすぎないか、今までやってきたことの振り返りを行います。
ドットマネー側の人間を巻き込むことで SRE を浸透させることが目的です。
サービス全体に SRE を浸透させる
どうやったらサービス全体に SRE を浸透できるかを考えていると、定例などはもちろんそうですが CS 対応をしている方、フロント、ビジネスサイドには中々難しいんでないかと思いました。
そこでサービス側の方、全員が参加する random チャンネルへ週に1回、SLOサマリーを投稿するツールを作成してみました。
は、Datadog API を使って SLO を取得し整形して Slack に投稿するシンプルなツールです。
コンテナイメージで公開しているので手軽に利用することができます。
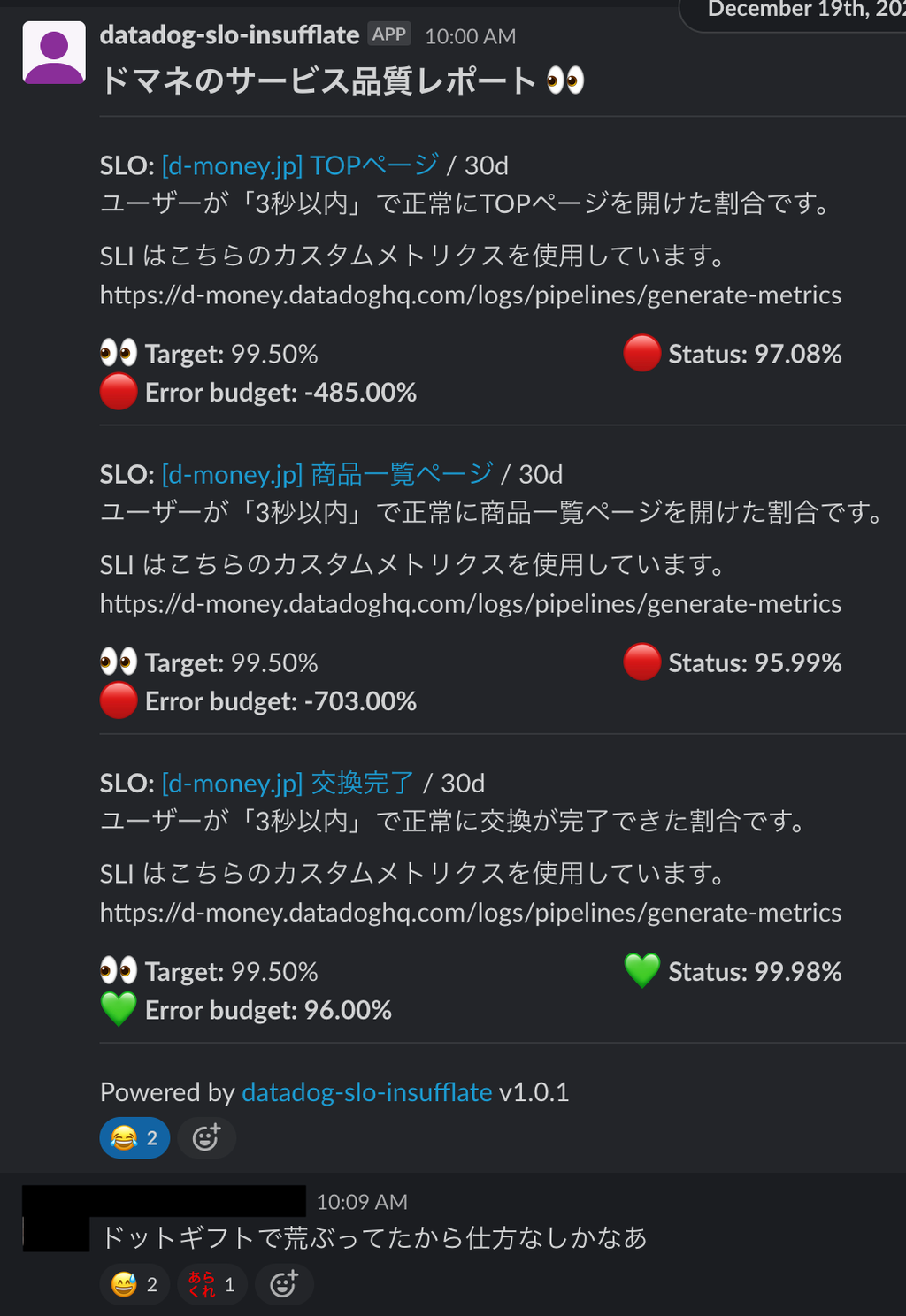

まだまだリアクション数が少ないですが当初に比べて反応してくれる方も増えました。
「ないよりはあったほうがいい」そんなツールです。
障害の話になりますが、SLO の値が日々悪くなっていくことがありました。
そしてある日、大規模な障害が起きました。
後述する Tips で紹介しているエラーバジェットバーンレートを導入する前だったので前もって気づけなかったのですが SLO の値が悪くなっていくといつか大爆発する、そんなことを学べました。
Tips
SLO に対するアラートはどうしたらいか
今回は SLO に対してアラートを設定はしておらず、今後も設定する予定はありません。
これは後述するエラーバジェットバーンレートに対してアラートを設定しているためです。
エラーバジェットバーンレート
バーンレートとは、Google の造語で、SLO の目標長に対してエラーバジェットがどの程度速く消費されるかを示す単位なしの値です。たとえば、30 日間を目標とする場合、バーンレートが 1 であれば、1 の割合が一定であれば、エラー予算がちょうど 30 日で完全に消費されることを意味します。消費率 2 とは、一定であれば 15 日、消費率 3とは 10 日でエラーバジェットが枯渇することを意味します。
バーンレートについては Datadog のドキュメントが分かりやすいです。
このエラーバジェットバーンレートはエラーバジェットに対して直接アラートを仕込めるため SLO に対してアラートを仕込む必要がなくなります。
またノイズアラートになりやすい 5xx エラーレートに対してのアラートも消せるため一石二鳥です。
実際にドットマネーで設定しているアラートはこのようになっています。
クエリ
メッセージ
short_window, long_window を同時に設定するクエリは Web 上からだとできないため Terraform(API) から設定を行いました。この記事を公開しているときには設定できているかもしれません。
を同時に設定している理由
short_window のみだとアラートの頻度が多くなりノイズになりやすく、long_window も条件に追加することでノイズを減らし信憑性のあるものにするためです。
終わりに
今回の記事は SRE 初心者である私がどうサービスに対して SRE を導入したかの体験記みたいなものでした。
SRE を導入するのは敷居が高いですが、とりあえずやってみるのが大事かなと思います。
もちろん、SRE は文化であり組織でもあるので導入したから終わりという話ではなくまだまだ物語は続きそうです。
私自身 SRE を完全には理解していませんが、最初は深く考えすぎずに導入し日々改善していくのが手っ取り早く SRE に対して知見が得られると思います。(先が見えにくく地味な作業が多いので…)
直近考えていることは SRE とビジネスインパクトの紐付けを可視化したいと思っています。
例えばエラーバジェットがなくなりマイナスになった際の売上高と、エラーバジェットがきれいに使われる(もしくは余る)ときの売上高の差を可視化、とその方法を決め本当に SRE がビジネスに対して影響があることを漠然とした世界から現実にしたいと思っています。
もしすでにやっている方がいましたらぜひ教えて下さい。
SRG では一緒に働く仲間を募集しています。
ご興味ありましたらぜひこちらからご連絡ください。