
我々はどのオープンウェイトモデルを選択したら良いのか。MoE?Q4?
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
本記事は、オープンウェイトや量子化、MoEなどの専門用語を解説して複雑なモデル選びの悩みを解決し、読者が自身のハードウェア環境に最適なAIモデルを迷わず選択できるようにするためのガイドです。
Qwen3.5 の性能が良いローカルLLMの使い道を考えるそもそも「オープンウェイト」とは何か「量子化」とは何か、なぜ必要なのか量子化の命名規則を読み解く各量子化レベルの特徴と使い所2bit 量子化(超軽量・実験的)3bit 量子化(軽量・実用的)4bit 量子化(バランス重視・最もポピュラー)5bit 量子化(高品質・やや大容量)6bit 量子化(高品質)8bit 量子化(ほぼ原精度)MoE(Mixture of Experts)とは何か動的量子化(Unsloth Dynamic)とは何かどの量子化を選べばよいかまとめ
Qwen3.5 の性能が良い
Qwen3.5 は Alibaba が開発しているオープンウェイトの最新モデルです。
筆者の環境(DDR5-6400 256GB + RTX4090 Gen4 x16)で unsloth/Qwen3.5-35B-A3B-GGUF:UD-MXFP4_MOE を動かすと thinking 有りで 143tps の速度が出ます。

Qwen3.5 はオープンウェイトモデルの中ではベンチマーク上ではダントツのスコアを誇ります。
ローカルLLMの使い道を考える
私は browser-use での利用、そして Brave Leo AI の BYOM で利用しています。
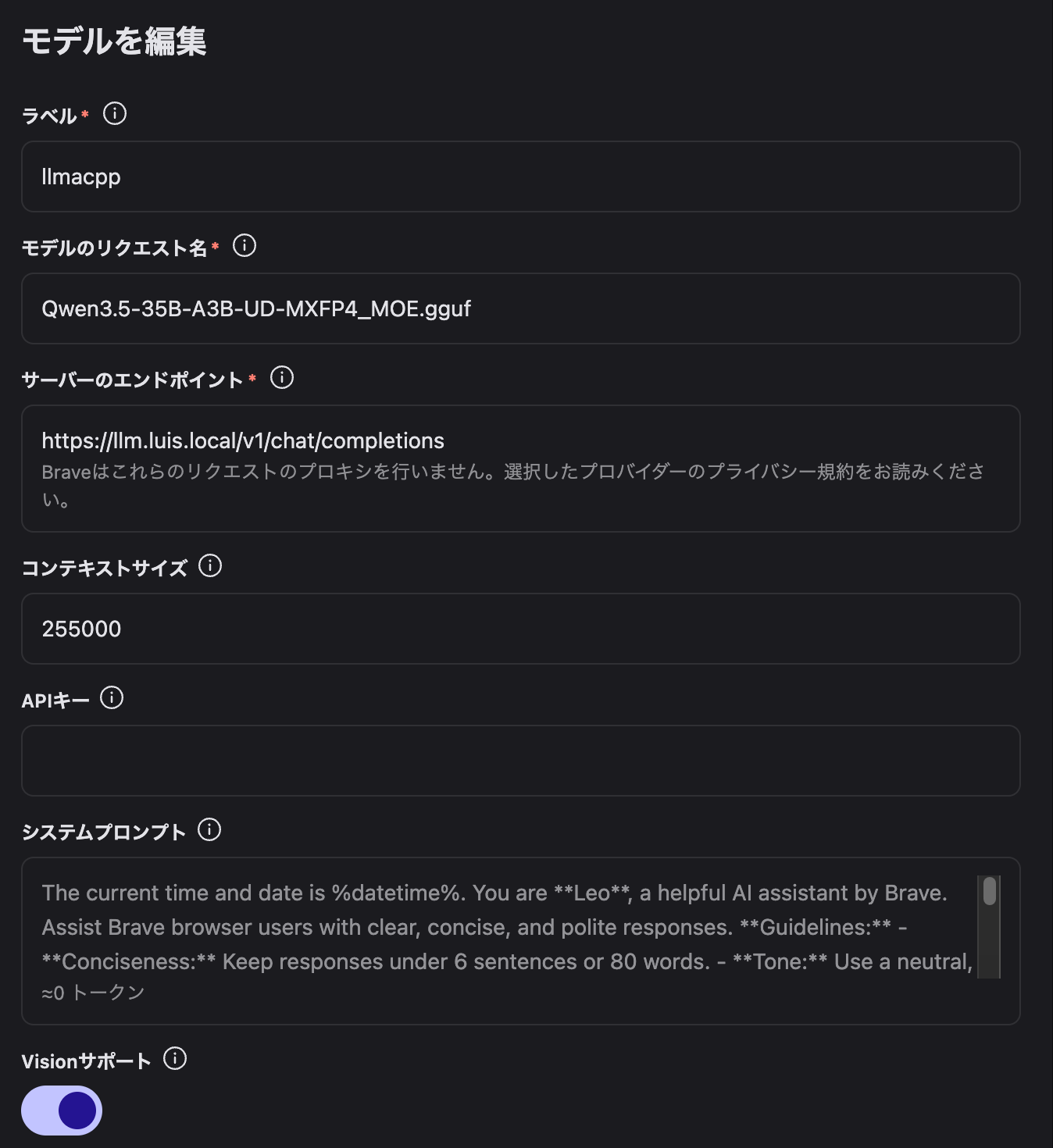
browser-use の用途では Gemini 3.1 Pro を利用していましたが全く差を感じません(体感)。
むしろローカル環境のおかげもありレスポンスが速くなりました。
そもそも「オープンウェイト」とは何か
最近、AI 界隈で「オープンウェイト」という言葉を耳にする機会が増えました。
「オープンソースと何が違うの?」と疑問に思う方も多いと思います。
オープンウェイトは、学習済みモデルの重みと推論に必要な最小限のコードのみを公開する形態です。
学習データセットや学習時の詳細な手順、ハイパーパラメータの詳細は公開されません。
つまり、企業や研究者が「モデルそのもの」をローカル環境でダウンロードして動かせるのがオープンウェイトの大きな特徴です。
入力したデータが外部に送られる心配がなく、ファインチューニングによる自社向けのカスタマイズも可能になります。
「量子化」とは何か、なぜ必要なのか
LLM のパラメータは、通常 bfloat16 や float32 といった高精度な浮動小数点数で表現されています。
しかし、これらをそのまま扱おうとすると、数十 GB 〜数百 GB ものメモリが必要になります。
そこで登場するのが「量子化(Quantization)」という技術です。
量子化とは、モデルの各重みを表現するビット数を減らすことで、ファイルサイズを小さくしてメモリ消費を抑える手法です。
例えば、通常 16bit で表現していた値を 4bit に圧縮すれば、単純計算でファイルサイズを約 4 分の 1 にできます。
ただし、情報を圧縮すれば精度はある程度失われます。
ビット数が小さいほどモデルは軽量になりますが、回答の品質が下がる可能性があります。
この「サイズ vs 品質」のトレードオフがオープンウェイト運用の核心です。
量子化の命名規則を読み解く
配布されているモデルのファイル名には や といった記号が並んでいます。
はじめて見ると暗号のように感じますが、構造を理解すると読めるようになります。
各記号の意味は次のとおりです。
- : Unsloth Dynamic の略。後述する動的量子化が適用されていることを示します。
- : Quantized(量子化済み)を意味します。
- 数字(例: 、): 1 つの重みを何ビットで表現するかを示します。数字が大きいほど高品質・大容量です。
- : K-means クラスタリングを使ったグループ量子化方式であることを示します。
- (例: ): Importance Matrix(imatrix)を活用した量子化であることを示します。重要度の高い層を優先的に保護します。
- / / / / / : サイズやブロックの大きさを示すサフィックスです。 が最も小さく(=最も攻撃的な圧縮)、 が最も大きく(=最も保守的な圧縮)なります。
各量子化レベルの特徴と使い所
以下は、今回対象とするモデルの量子化一覧です。
ここでは unsloth/Qwen3.5-35B-A3B-GGUF を例にします。
2bit 量子化(超軽量・実験的)
| 名称 | サイズ |
|---|---|
| UD-IQ2_XXS | 9.76 GB |
| UD-Q2_K_XL | 12.9 GB |
1 つの重みをわずか 2bit 前後で表現する最も攻撃的な圧縮です。
VRAM が限られた環境でも大規模モデルを動かせるという点が魅力ですが、回答品質への影響が大きくなります。
ただし、動的量子化(UD)を組み合わせることで、重要な層は高精度のまま維持され、想定以上の品質が得られる場合があります。
実際のベンチマークでは、Unsloth の UD-Q2_K_XL が標準的な 3bit 量子化(Q3_K_M)を複数のベンチマークで上回る結果も報告されています。
は と比べてやや大きいですが、品質とサイズのバランスが良いため、2bit を選ぶ場合のファーストチョイスとして推奨されることが多いです。
3bit 量子化(軽量・実用的)
| 名称 | サイズ |
|---|---|
| UD-IQ3_XXS | 14.1 GB |
| UD-IQ3_S | 15.2 GB |
| UD-Q3_K_M | 16.7 GB |
| UD-Q3_K_XL | 17.2 GB |
2bit と 4bit の中間に位置する量子化です。
は 16GB VRAM の GPU でも動作可能なサイズであり、コンシューマー向け GPU で大型モデルを動かしたい場合の選択肢となります。
は より若干大きいですが、動的量子化の恩恵で重要な行列に高精度を割り当てており、品質面で有利です。
3bit の中では サフィックスがついたものを選ぶのが基本的な推奨です。
4bit 量子化(バランス重視・最もポピュラー)
| 名称 | サイズ |
|---|---|
| UD-MXFP4_MOE | 19.5 GB |
| UD-Q4_K_M | 19.9 GB |
| UD-Q4_K_XL | 20.6 GB |
4bit 量子化は「品質とサイズのバランスが良い」として最もよく使われるレベルです。
は Unsloth の開発者が「ほとんどのハードウェアで最初に試すべき選択肢」として推奨しているバリアントです。
重要な行列には Q5_K など高精度の量子化を割り当てながら、それ以外は Q4_K を使うことでサイズを抑えています。
は MoE(後述)向けに最適化された特殊な 4bit 量子化です。
MXFP4(Microscaling FP4)は OCP(Open Compute Project)が策定した規格で、OpenAI の gpt-oss-120b でも採用されています。
専用ハードウェア(NVIDIA Blackwell 世代など)で特に効率的に動作します。
5bit 量子化(高品質・やや大容量)
| 名称 | サイズ |
|---|---|
| UD-Q5_K_XL | 24.9 GB |
4bit よりさらに品質を求める場合に選択します。
専門家の中には「int4(4bit 整数)量子化で十分」という意見もありますが、コーディングや論理推論など精度が求められるタスクでは 5bit 以上の恩恵を感じるケースもあります。
6bit 量子化(高品質)
| 名称 | サイズ |
|---|---|
| UD-Q6_K_S | 28.5 GB |
| UD-Q6_K_XL | 30.3 GB |
品質劣化がほぼ感じられないレベルです。
は KL Divergence(モデルの確率分布のズレ指標)が非常に低く、元モデルとほぼ同等の出力分布を保ちます。
8bit 量子化(ほぼ原精度)
| 名称 | サイズ |
|---|---|
| UD-Q8_K_XL | 38.7 GB |
8bit はフルプレシジョン(16bit)に非常に近い品質です。
パープレキシティ(文章の予測困難度)の増加がほぼゼロに近く、研究・検証目的や VRAM に余裕がある環境で選ばれます。
MoE(Mixture of Experts)とは何か
量子化とともに重要なのが「MoE」アーキテクチャです。
MoE(混合エキスパート:Mixture of Experts)とは、モデルの内部に複数の「エキスパート」(専門家)となるサブネットワークを持たせ、入力トークンごとに一部のエキスパートだけを活性化する仕組みです。
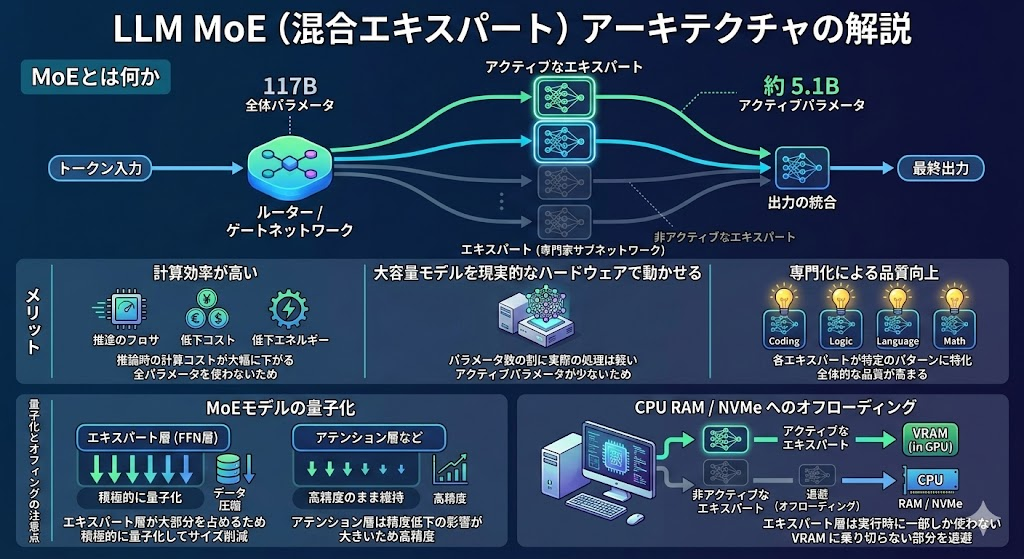
たとえば 120B パラメータを持つモデルでも、MoE アーキテクチャの場合は各トークンの処理に実際に使われるパラメータ(アクティブパラメータ)は全体の一部に過ぎません。
OpenAI の gpt-oss-120b の場合、全体は 117B パラメータですが、アクティブパラメータは約 5.1B です。
この仕組みのメリットは次のとおりです。
- 計算効率が高い:全パラメータを使わないため、推論時の計算コストが大幅に下がります。
- 大容量モデルを現実的なハードウェアで動かせる:「パラメータ数の割に実際の処理は軽い」という特性があります。
- 専門化による品質向上:各エキスパートが特定のパターンに特化することで、全体的な品質が高まります。
MoE モデルの量子化では注意点があります。
エキスパート層(FFN 層)はモデル全体のパラメータの大半を占めるため、ここを積極的に量子化することがサイズ削減の鍵となります。
一方、アテンション層などは精度低下の影響が大きいため、高精度のまま維持するのが一般的です。
また、MoE モデルは CPU RAM への「オフローディング」と相性が良い点も特徴です。
エキスパート層は実行時に一部しか使われないため、VRAM に乗り切らない部分をシステム RAM や NVMe に退避させながら動かすことが可能です。
動的量子化(Unsloth Dynamic)とは何か
というプレフィックスで始まるモデルはすべて「動的量子化(Unsloth Dynamic)」が適用されています。
従来の一律量子化では、すべての層を同じビット数で圧縮します。
しかし動的量子化では、モデルのどの層が出力に大きな影響を与えるかを事前に分析し、重要度の高い層は高精度(例: 8bit や 16bit)に、重要度の低い層は低精度(例: 2bit や 3bit)に自動的に割り当てます。
この仕組みにより、「同じファイルサイズでも品質が高い」あるいは「同じ品質でもファイルサイズが小さい」という恩恵が得られます。
動的量子化の実現には imatrix(Importance Matrix)と呼ばれるキャリブレーションデータが活用されます。
Unsloth は会話・コーディング・推論タスク向けに最適化された独自のキャリブレーションデータセットを使用しており、これが品質向上に貢献しています。
実際のベンチマーク結果でも、Unsloth の UD-IQ2_XXS が他社製の IQ3_S よりも実際のタスク精度が高いケースが報告されており、パープレキシティ値や KL Divergence 値だけでは実運用での品質を正確に評価できない場面もあります。
サフィックスについても補足します。
は と比べて、重要な行列に Q5_K を割り当てるのが「安全」と判断した場合に自動的にアップキャストします。
多くの行列は Q4_K のままですが、出力に大きな影響を与える一部の層が高精度になることで、体感品質が向上します。
どの量子化を選べばよいか
ハードウェアの状況に応じた目安を整理します。
VRAM が 16GB 程度の場合は、 が動作上限の目安となります。
コンテキスト長を 8192 程度に制限することで安定した推論が可能です。
VRAM が 24GB 程度の場合は、 が品質とサイズのバランスが最も取れた選択です。
まとめ
本記事は、オープンウェイトと量子化、MoE について解説しました。
VRAM16GB 以上なら UD-IQ3_XXS や UD-Q4_K_XL が推奨されます。
MoE は計算効率が高く、ローカル推論に適しています。最適な AI モデル運用を実現しましょう。
SRGにご興味ありましたらぜひこちらからご連絡ください。