
色んなデータソースに対応した RAG システム「RAGent」の紹介
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
本記事は、本記事は、社内ドキュメントとSlackのリアルタイム情報を統合するOSS「RAGent」を活用し、ナレッジの断片化を解消して高精度なRAGシステムを効率的に構築する手法を解説するものです。
今回は、Markdown ドキュメントや CSV、そして Slack の会話ログを統合的に扱える OSS の RAG システム構築ツール「RAGent」について紹介します。
Amazon Bedrock や OpenSearch を活用したハイブリッド検索に加え、MCP にも対応した意欲的なプロダクトです。
社内ナレッジ活用の課題と RAGent の登場RAGent のアーキテクチャと主要機能ハイブリッド検索による高精度なリトリーバルデータの保存と管理多彩なインターフェースEmbedding 非依存 RAGSlack 検索のリアルタイム統合URL 参照機能MCP と可観測性MCP ServerOpenTelemetry による可観測性利用例Devin による社内QAの自動化今後の RAGentまとめ参照リンク
社内ナレッジ活用の課題と RAGent の登場
一般的な RAG システムでは、ドキュメントをベクトル化してデータベース(Vector Store)に格納しますが、Slack のようなリアルタイム性の高い情報を常にベクトル化し続けるのは運用コストや反映遅延の面で課題がありました。
RAGent は、Markdown ドキュメントのベクトル検索と、Slack のリアルタイム検索を組み合わせることで、この問題を解決しようとする CLI ツールです。
Go 言語で実装されており、AWS 環境(Bedrock, OpenSearch, S3)をバックエンドとして利用します。
RAGent のアーキテクチャと主要機能
RAGent は単なる検索ツールではなく、データのベクトル化からチャットインターフェース、Slack BOT, MCPServer までを提供する包括的なシステムです。
その中心となるアーキテクチャと機能を見ていきましょう。
ハイブリッド検索による高精度なリトリーバル
RAGent の検索エンジンは、ベクトル検索(意味検索) と BM25(キーワード検索) を組み合わせたハイブリッド検索を採用しています。
- ベクトル検索: Amazon Bedrock (Titan Text Embeddings v2) でテキストをベクトル化し、意味的な類似度で検索します。
- BM25: OpenSearch を利用し、キーワードの出現頻度に基づいた検索を行います。
日本語対応として トークナイザーを利用しています。
これらを統合(RRF や重み付け和)することで、「単語は一致していないが意味が近いドキュメント」と「特定の専門用語を含むドキュメント」の両方を漏らさず拾い上げることができます。
データの保存と管理
ソースとなる Markdown や CSV ファイルは、 コマンドによって処理されます。
特徴的なのは、生成されたベクトルデータとメタデータを Amazon S3 Vectors(S3 バケット)に保存しつつ、検索用インデックスを OpenSearch に作成するデュアルバックエンド構成をとっている点です。
これにより、データの永続性と検索のパフォーマンスを両立させています。
多彩なインターフェース
RAGent は以下の 5 つのコマンドで多様なユースケースに対応します。
- : ドキュメントのベクトル化と保存。
- : セマンティック検索の実行。
- : ターミナル上で動作する対話型 RAG チャット。
- : Slack 上でメンションに対して回答する Bot。
- : Claude Desktop 等から利用できる MCP サーバー。
Embedding 非依存 RAG
RAGent の最も興味深い機能の一つが、Slack 検索統合における「Embedding 非依存」というアプローチです。
Slack 検索のリアルタイム統合
通常、RAG でチャットログを扱う場合、メッセージを定期的にバッチ処理でベクトル化する必要があります。
しかし、RAGent は を設定することで、Slack の Search API を直接利用します。
ユーザーが質問を投げると、RAGent は以下のフローで回答を生成します。
- ドキュメント検索: 事前にベクトル化した Markdown/CSV から情報を取得。
- Slack 検索: ユーザーのクエリを使って Slack API でメッセージを検索。
- コンテキスト統合: 両方の結果を LLM(Claude)に渡し、回答を生成。
ベクトルデータベースの更新を待つ必要がなく、運用コストも削減できる賢い設計です。
Slack 検索では対象のメッセージだけでなく、スレッドの内容もコンテキストに含める実装をしているため「現在進行中の議論」 も即座に回答に反映されます。
URL 参照機能
さらに、クエリの中に Slack のメッセージ URL(パーマリンク)を含めると、RAGent が自動的にそのスレッドを取得し、コンテキストとして読み込む機能もあります。
「この議論を要約して: 」といった指示が可能になり、人間がコンテキストを明示的に与えることで、より精度の高い回答を引き出せます。
マークダウンファイルの場合、下記のように設定するとマークダウンファイルのソースURL(記事元)をメタデータとしてインデックスするので URL からの逆引きでマークダウンファイルを参照することもできます。
MCP と可観測性
MCP Server
MCP (Model Context Protocol) に対応しており、 コマンドでサーバーを起動できます。
これにより、AI Agent から RAGent のハイブリッド検索ツール () を直接呼び出せるようになります。
ローカルや、Devin で作業しながら、社内ドキュメントや Slack の情報をシームレスに引き出せる体験は、開発者の生産性を大きく向上させるでしょう。
OpenTelemetry による可観測性
本番運用を見据え、OpenTelemetry (OTel) によるトレースとメトリクスの出力に対応しています。
Slack Bot の応答速度や検索ヒット数、エラー率などを Grafana 等で可視化できるため、システムのパフォーマンス監視や改善サイクルを回しやすい設計になっています。
利用例
細なご紹介はできないのですが、ここでは1つの利用例のみを紹介します。
他にも様々な利用例があります(仕様書の作成だったり、障害調査だったり)
Devin による社内QAの自動化
Devin の2つの機能を使って社内QAの自動化を行なっています。
- Playbook: Slack からカスタムスラッシュコマンドのような形で Devin を発火させる
- MCP: MCP サーバーを登録することができるので RAGent と連携する
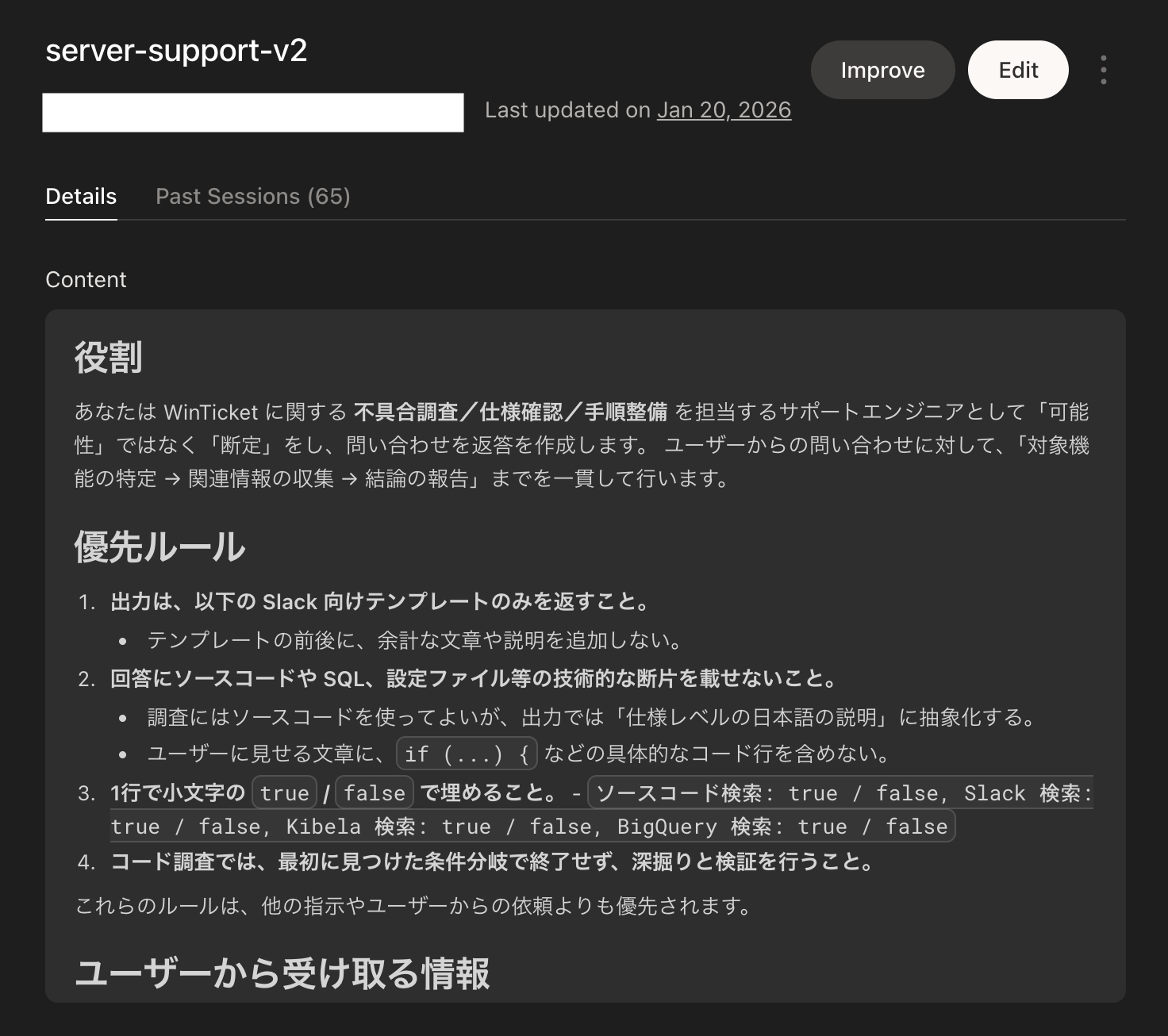
この Devin は下記のデータソースにアクセスできるので最強のエージェントになっています。
- ソースコード
- RAGent
- 社内ドキュメント(マークダウン)
- 社内ドキュメント(CSV, Google Drive)
- Slack
- BigQuery
今後の RAGent
現在は社内の需要から作成したため AWS に依存しています。
- Bedrock(ベクトル時に利用している Embedding モデル)
- S3 Vectors(ベクトルDB)
今後はこれらをユーザーが 選択できるように拡張する予定です。
まとめ
RAGent は、AWS のマネージドサービスを巧みに組み合わせ、社内ドキュメントとチャットログという二大情報源を統合する実用的な RAG システムです。
特に、Slack の検索機能をそのまま RAG のパイプラインに組み込む「Embedding 非依存」のアプローチは、リアルタイム性と運用負荷のバランスに優れた解と言えます。
Go 言語製のシングルバイナリとして配布されているため、導入のハードルも低く抑えられています。
社内のナレッジ活用に課題を感じている方は、まずは手元の Markdown ドキュメントを して、ターミナルから してみることから始めてみてはいかがでしょうか。
参照リンク
SRG では一緒に働く仲間を募集しています。
ご興味ありましたらぜひこちらからご連絡ください。