
0から始めるインシデントマネジメント -導入編 その2-
メディア統括本部 サービスリライアビリティグループ(SRG)の田中(@tako_sonomono)です。
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
はじめにインシデントオーナーに求められる「解像度」インシデントライフサイクルの全体像運用フェーズにおける課題と対策1. 情報資産の管理場所 (Single Source of Truth)2. コミュニケーション・チャネルの設計3. チケット更新の形骸化とトイル終わりに
はじめに
昨年の記事では、インシデントマネジメントにおける「インシデントオーナー」「インシデントコマンダー」の確立や「トリアージ」の意思決定プロセスについて論じました。
これらはインシデント初期対応における「点」の議論でしたが、今回はその後の解決に至るまでの「線」、すなわちワークフローの定義と、それを実際の組織で回す際の運用課題について掘り下げます。
本稿では、インシデントオーナーが既存のフローをどのように解像度高く把握すべきか、そして運用開始後に直面するコミュニケーション設計や記録の課題について、SREの原則を交えながら解説します。
インシデントオーナーに求められる「解像度」
SREの観点において、効果的なインシデント管理の要素の一つに「Defined Process」が挙げられます。緊急時における認知負荷を下げるためには、事前に合意された明確な手順が不可欠になります。
インシデントオーナーは大前提として、既存のフローを組織内の誰よりも正確に把握している必要があります。なぜなら、汎用的なフレームワークには現れない、その事業特有の「独自のルール」や「連携」には必ず歴史的・事業的な背景(Context)が存在するからです。 これらを含めた全容を把握していなければ、コマンダーとしてメンバーの行動を指針付けすることができず、また「なぜその手順が必要なのか」という問いに対して合理的な回答ができません。
理解度を向上させ、属人化を防ぐためにも、まずは自身の言葉でワークフローを図解し、Playbookとしてドキュメント化することを推奨します。
インシデントライフサイクルの全体像
インシデントフローは組織規模や事業の性質により異なります。Amebalifeにおける特定事業のインシデントフローを一例として実務レベルに落とし込むと以下の13フェーズに分類されます。
- 問題発生: ユーザー影響やシステム異常の開始
- 検知: アラート発火、またはCSへの問い合わせ着弾
- 反応: オンコール担当者やCSによる認知
- チケット化: インシデント管理ツール(Jira/ServiceNow等)での起票
- トリアージ: 影響範囲の特定、SEV(重症度)決定、体制構築
- 一次報告: コミュニケーションツール(Slack等)での第一報
- ユーザーコミュニケーション: 障害発生報告(ステータスページ更新、お知らせ掲載)
- 復旧対応: 調査、Fix作成、Deploy
- 暫定復旧: サービスレベルが許容範囲内に戻った状態
- ユーザーコミュニケーション: 復旧報告(ステータスページ更新、お知らせ掲載)
- Postmortem: 振り返り、RCA(根本原因分析)
- 恒久対応: 再発防止策の実装
- クローズ: チケットの完了
このフローから明白なのは、インシデント対応はエンジニアリング領域に留まらないという点です。
特にフェーズ7や10におけるCS・広報・ビジネスサイドとの連携は、「ユーザーから見たサービスの信頼性」と言う観点ではシステム復旧と同等の重要性があります。
※実際に作成したワークフロー
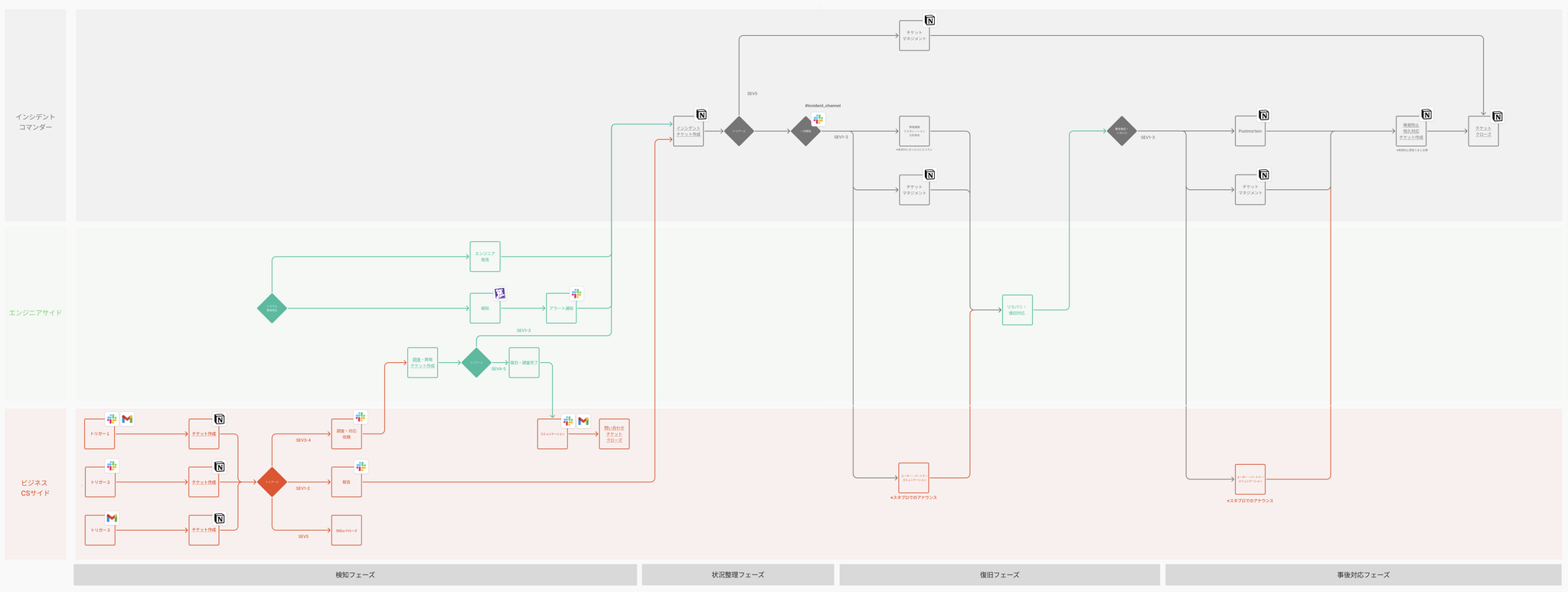
各セグメント(IC/エンジニア/ビジネス)で分けてフローを作成することを推奨
運用フェーズにおける課題と対策
理想的なフローを定義しても、実際の運用では「人間」という不確定要素がボトルネックとなります。運用開始後に直面する主要な課題と、そのアプローチについて記述します。
1. 情報資産の管理場所 (Single Source of Truth)
運用フロー、Tips、連絡網などのドキュメント管理は任意のツールで構いませんが、重要なのはDiscoverability(発見可能性)です。緊急時に迷わずアクセスできる場所に配置する必要があります。
2. コミュニケーション・チャネルの設計
インシデント対応中の議論(War Room)をどこで実施するかは、情報の透明性とキャッチアップコストのトレードオフとなります。
- チケット内: 記録性は高いが即時性に欠ける。
- Slackスレッド: 手軽だが、情報量が増えると可読性が著しく低下する。
- Slack専用チャンネル(Spot): 推奨
SEVが高い(影響度が大きい)インシデントに関しては、専用のSpotチャンネルを作成し、そこで情報を集約すべきです。 これは「認知負荷」の観点から推奨されます。
Slackのスレッド形式での議論は、時系列が追いづらく、後から合流した支援者や意思決定者のキャッチアップコストを増大させます。専用チャンネルであれば、情報のノイズを分離でき、ChatOpsなどのBot連携も容易になります。
3. チケット更新の形骸化とトイル
「インシデント対応中はチケットを更新する余裕がない」という事象は、多くの組織で発生します。しかし、チケットの更新が滞れば、ステークホルダーへの状況共有が遅れ、結果としてエンジニアへの個別問い合わせ(割り込みタスク)が増加します。
また、将来的なデータ分析やPostmortemの質も低下します。
この課題に対し、人力での完全な同期を強いるのは現実的ではありません。
これはSREが排除すべきトイルの一種と捉えるべきです。
現在、「Slack上のやり取り・会話ログからのサマリ自動生成・チケット更新」を行うためのワークフローの確立を推進しています。
終わりに
今回はインシデントマネジメントにおけるプロセスの定義と運用課題について整理しました。
インシデントマネジメント推進する際、ついツールの選定を先行して進めがちですが、本質はインシデントオーナーが「現状(As-Is)」を正確に把握し、どこにボトルネックがあるかを特定できているかに尽きます。 「人は情報整理を伴う運用を自律的には行えない」という前提に立ち、いかにシステムやAIを活用してプロセスの信頼性を担保していくかが今後のインシデントマネジメントにおける焦点になります。
SRGにご興味ありましたらぜひこちらからご連絡ください。