
[新機能]AWS DevOps Agentを使った自動障害対応検証と注意点
本記事は100%人間が執筆しています。
メディア統括本部 サービスリライアビリティグループ(SRG)の鬼海雄太(@fat47)です。
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
re:Invent 2025で発表されたDevOps Agentについて検証結果をまとめました。
AWS DevOps AgentとはDevOps Agentを使ってみるまでの手順0. 準備1. DevOps Agent Spaceの作成2. DevOps Agentによる調査を指示DevOps Agentの現状の注意点1. DevOps Agentのスコープは障害の根本原因調査・復旧策の提案・予防策の提案までで、復旧や予防策のコマンド実行はスコープ外2. プレビュー期間中の利用料金は無料だが制限がある3. 初期状態だと障害調査の指示をDevOps AgentのUI画面から出さないと調査してくれない4. モニタリングサービス側対応状況の違い5. EC2サーバーの中までは調査できない終わりに
AWS DevOps Agentとは
DevOps Agent はre:Invent 2025で発表された新機能で、メトリクスやログから障害の根本原因を特定して、緩和策の提案・予防策の提案をすることができるAIエージェントです。
現在はパブリックプレビューとしてバージニア北部(us-east-1)リージョンのみ利用可能となっています。
アラート検知元やテレメトリの収集対象としてCloudWatchはもちろんのことながら、以下のモニタリングサービスと連携することも可能です。
- Datadog
- Dynatrace
- New Relic
- Splunk
詳細はAWS公式のブログをご参照ください。
DevOps Agentを使ってみるまでの手順
0. 準備
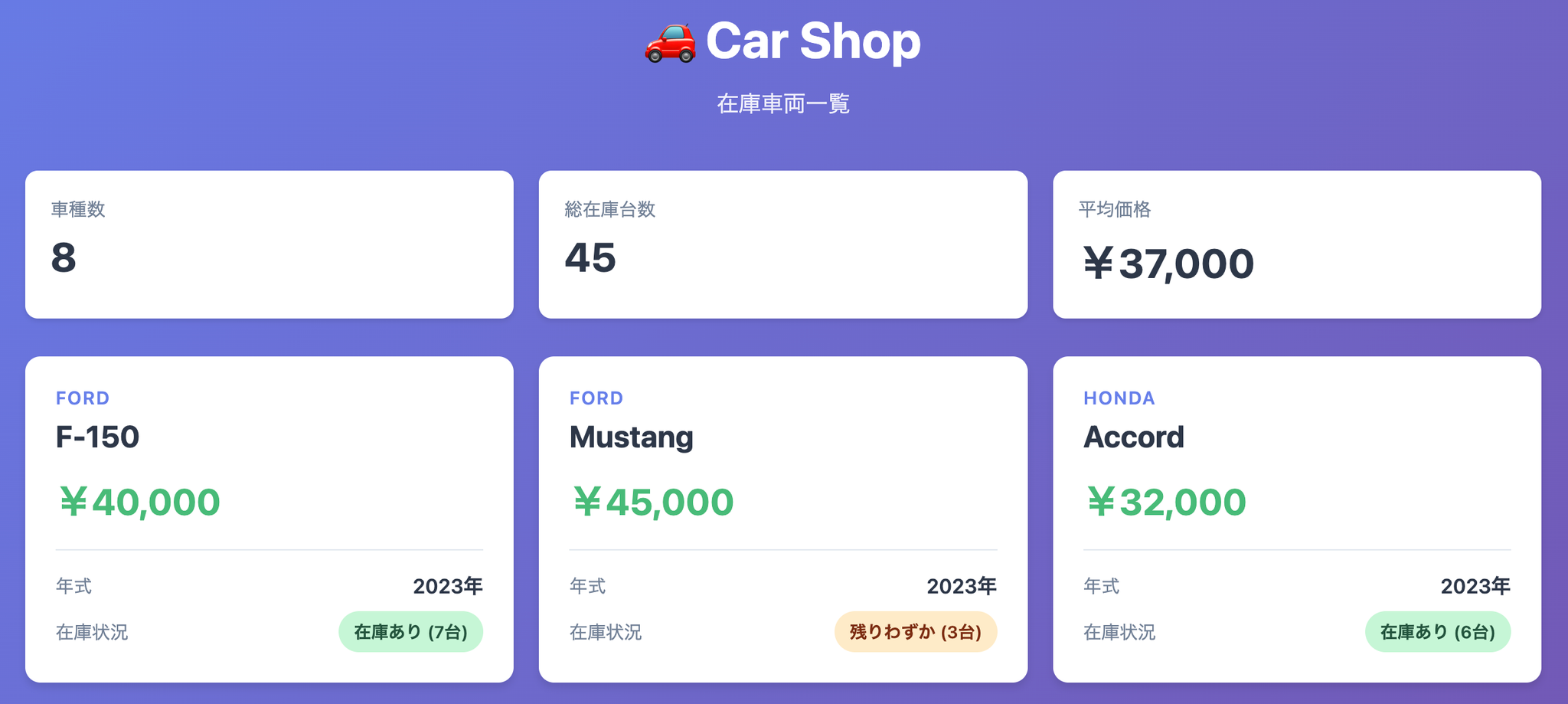
障害調査のイメージがしやすいように簡素なWebシステムをつくりました。
車の在庫一覧が表示されるだけの機能をもったWebシステムです。
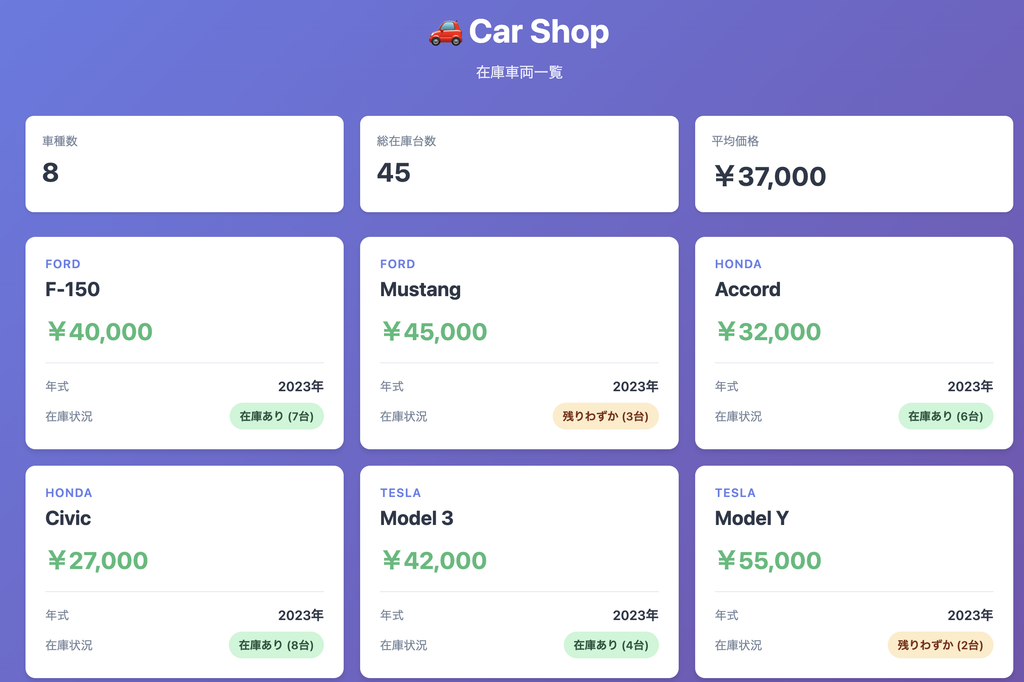
構成要素は以下の通りです。
- Cloudfront
- S3
- API Gateway
- Lambda
- Aurora MySQL Serverless v2
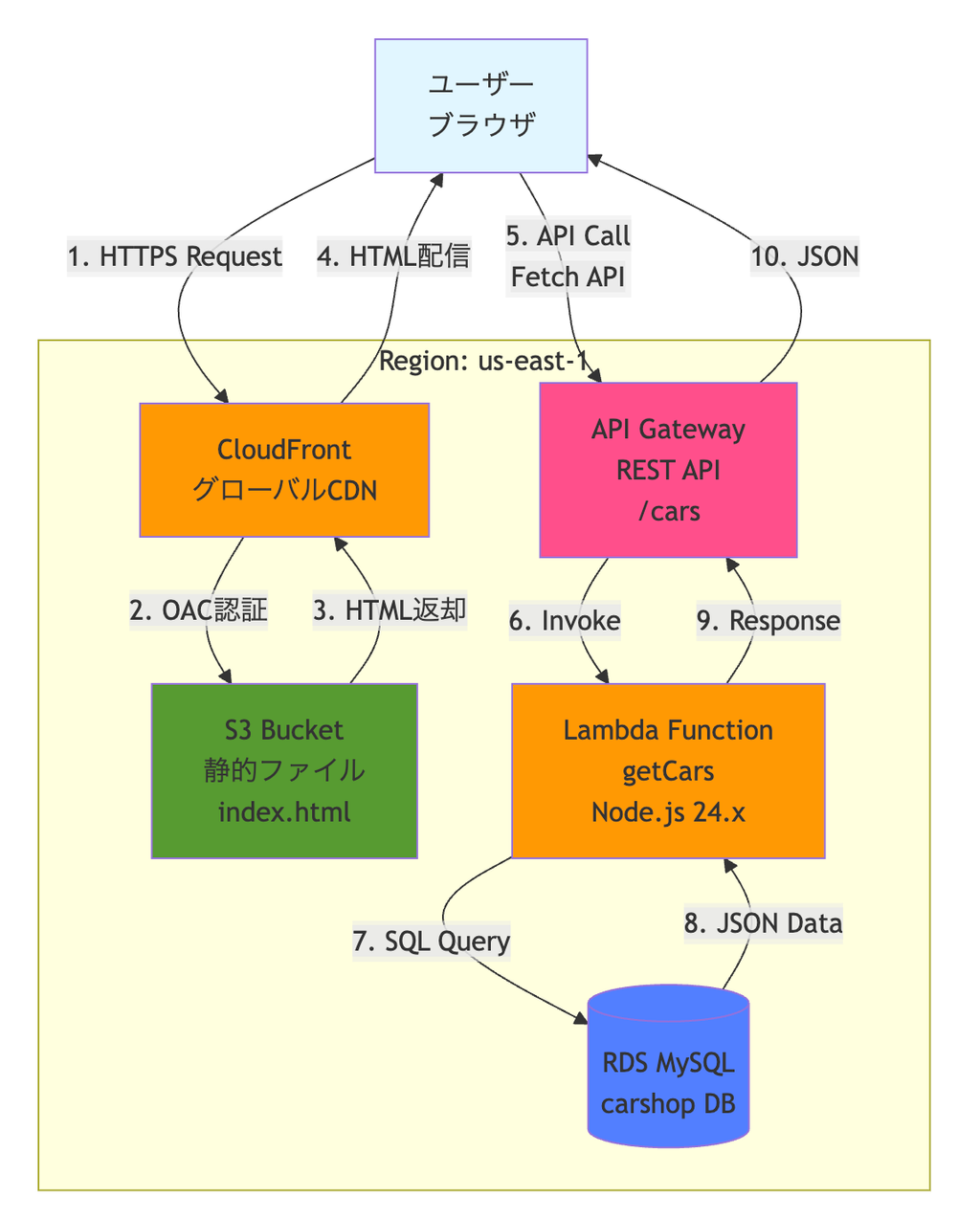
ユーザーがWebシステムにアクセスするたびに、LambdaがAurora MySQLにSELECTクエリを実行します。
構成要素に書いていませんが、CloudWatchアラームの設定でLambdaとAPI Gatewayのアクセスログのエラーをアラーム設定しておきます。
1. DevOps Agent Spaceの作成
リージョンをus-east-1にして、DevOps Agentを開いてBegin Setupをクリックします。
適当なAgent Space名を入力し作成します。
他の入力は今回はデフォルトのままで良いです。
作成されると以下のような画面になるので、「Operator Access」をクリックします。
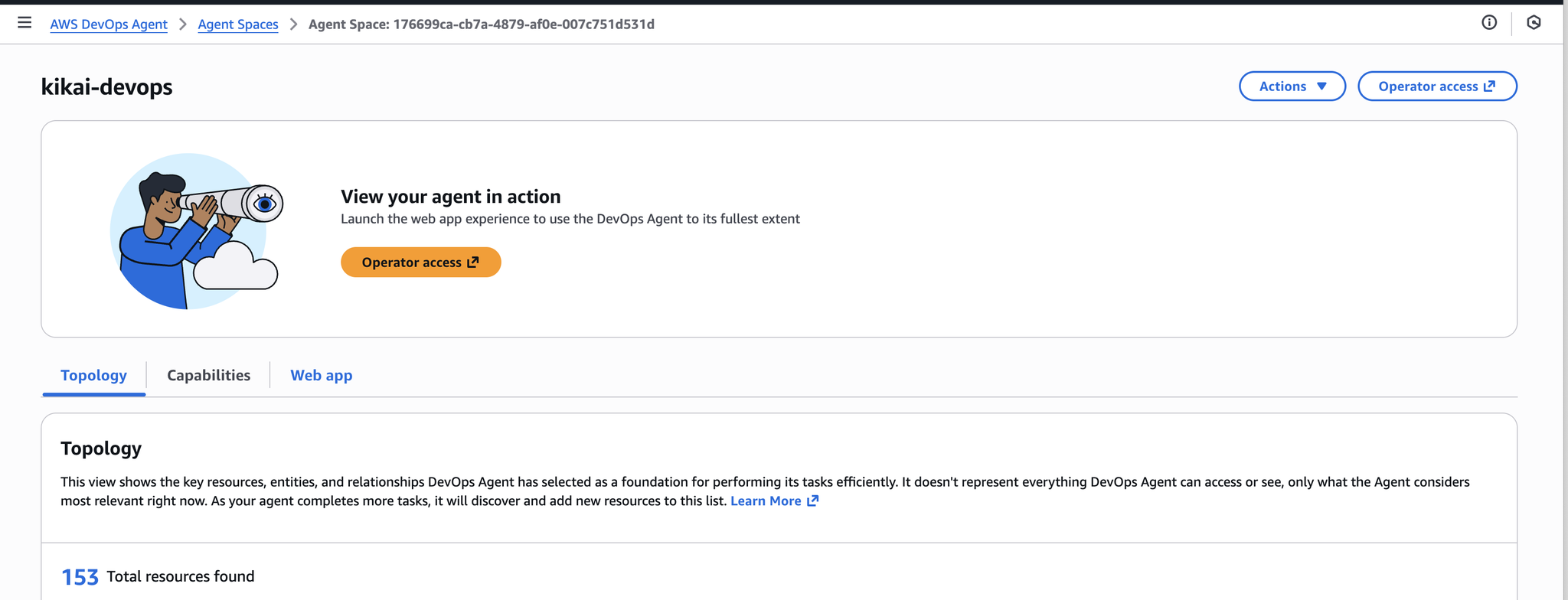
これだけで最低限の設定は完了です。
次にDevOps Centerのタブを開いてみましょう。

ShowをCompornentsに切り替えると、そのAWSアカウント内で稼働しているコンポーネントを確認することができます。
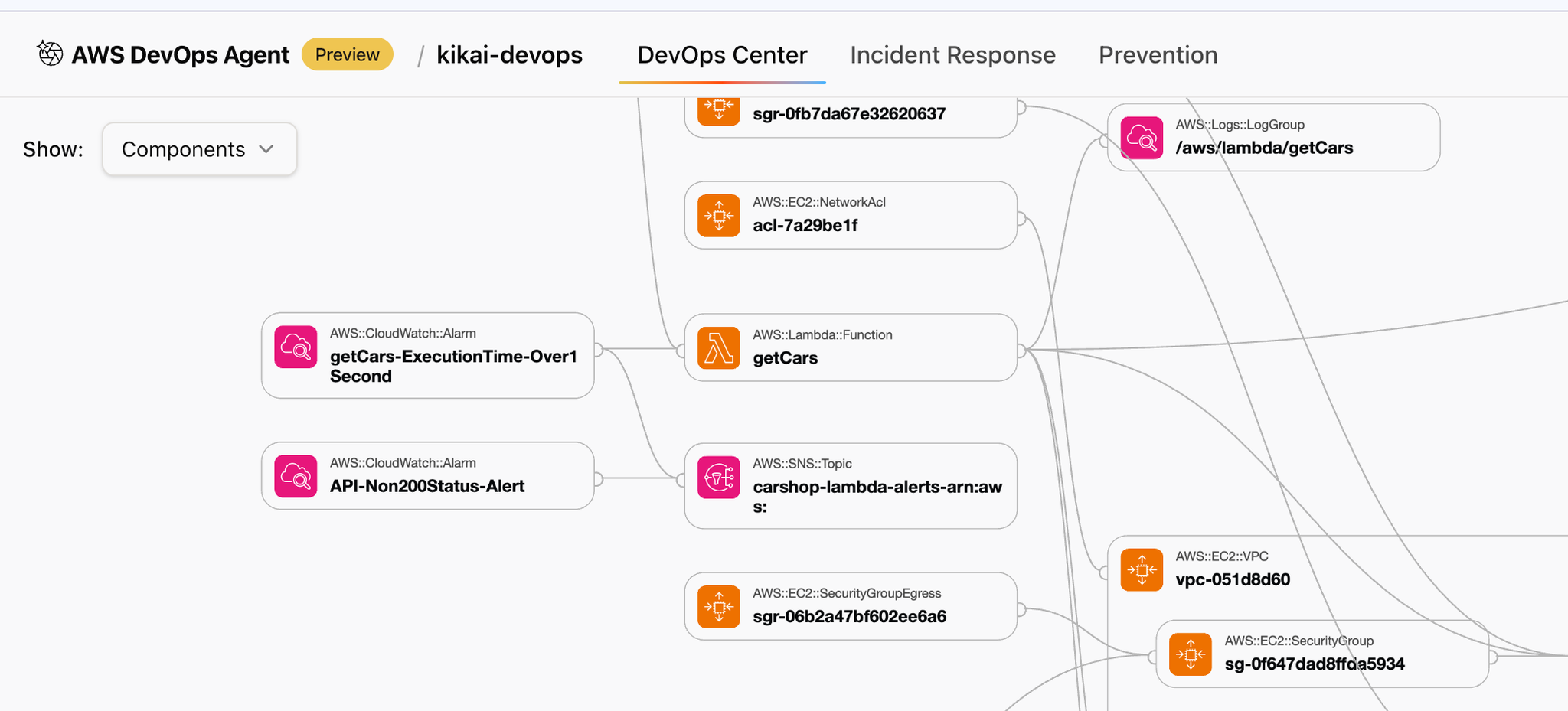
2. DevOps Agentによる調査を指示
まずは意図的に障害を発生させてみます。
Aurora MySQLが利用しているセキュリティグループで、Lambdaからのアクセスを許可している部分を削除してみます。

これによって、Lambda→Aurora MySQLの部分でアクセスができず、Webシステムがエラーとなりました。

事前に設定しておいたCloudWatchアラームを確認してみると、LambdaとAPI Gatewayのアラームがなっていることが確認できます。
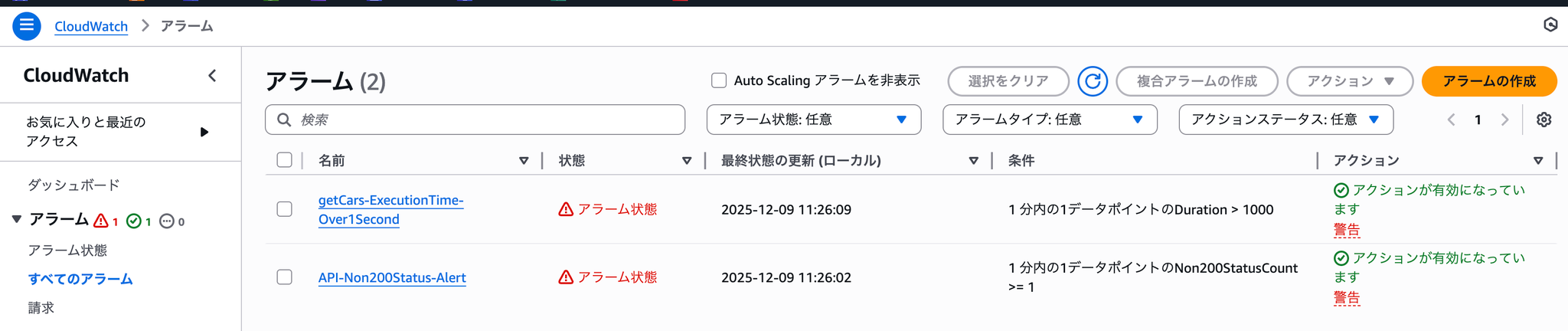
では、DevOps Agentに障害調査を依頼してみましょう。
DevOps Agentのインシデントレスポンスのタブで障害調査の指示を出します。(英文のみ)
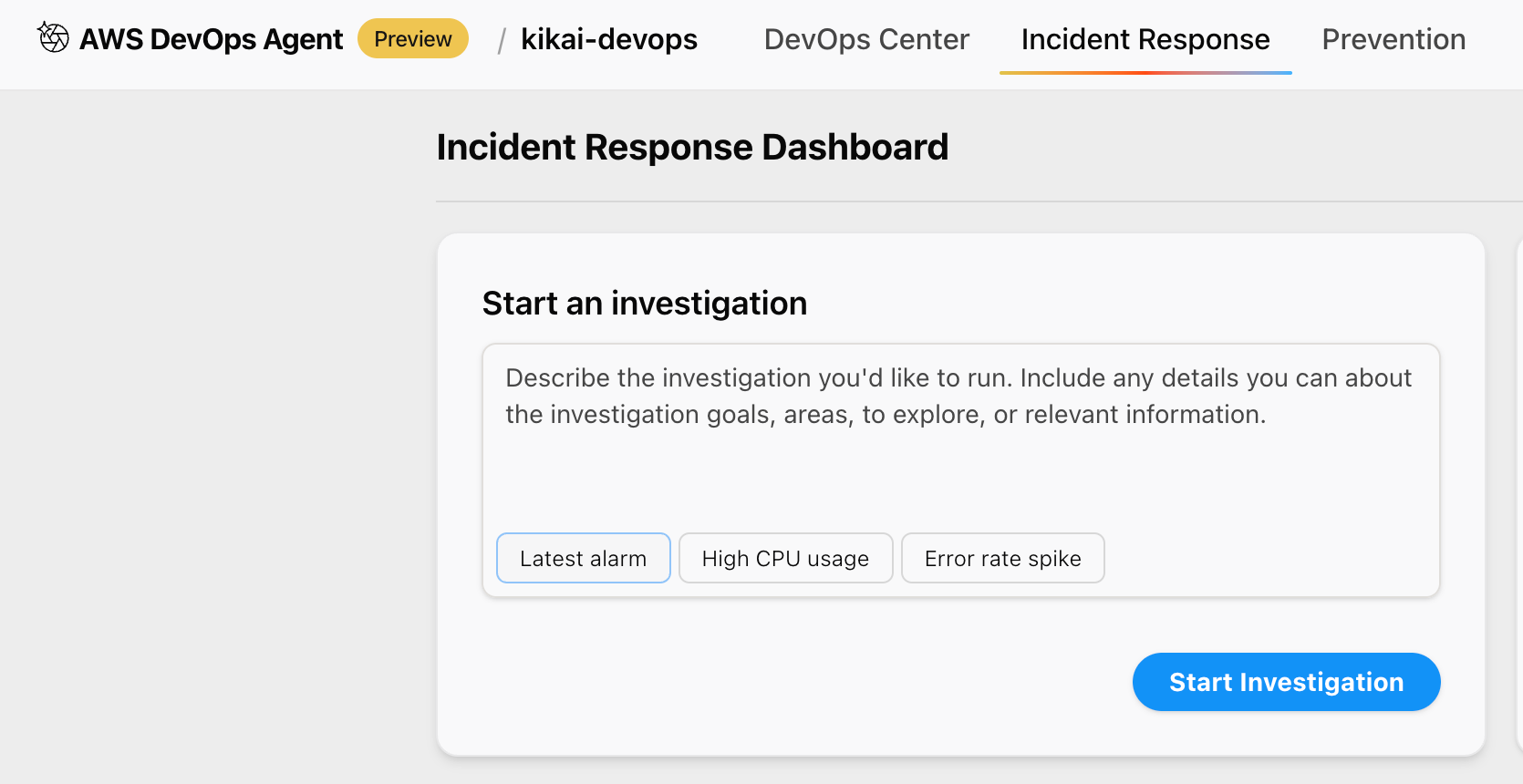
入力しなくても、表示されているボタンの[Latest alarm]をクリックすると、いい感じの指示が作成されます。
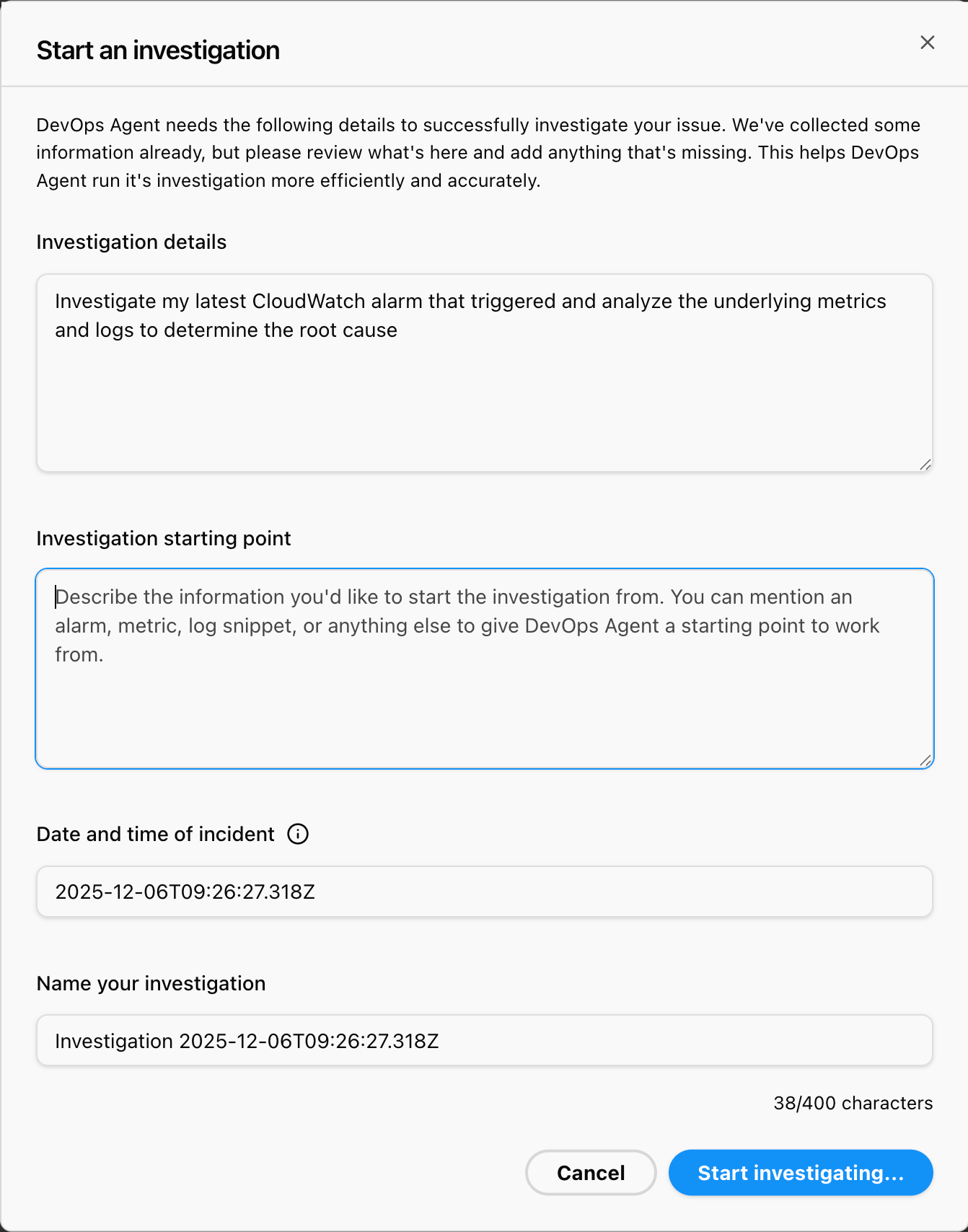
Investigation details:
以上を入力したら、Start investigatingをクリックします。
すると、リアルタイムでどんどん調査を進めていく様子が確認できます。
このまま完了まで数分待ちます。
数分後、原因にたどり着いたようです。
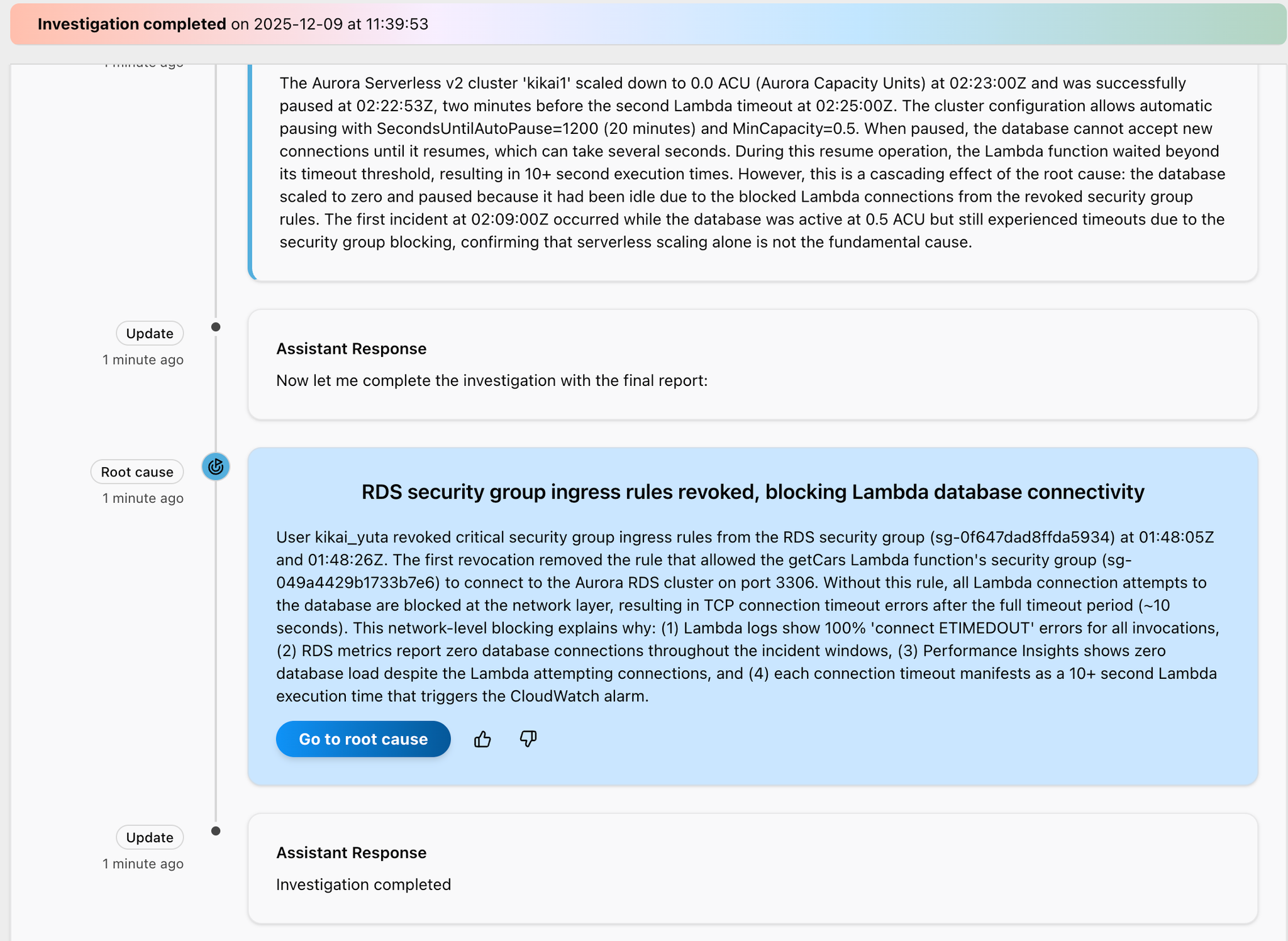
ユーザー kikai_yuta は、01:48:05Z と 01:48:26Z に RDS セキュリティグループ(sg-0f647dad8ffda5934)から重要なセキュリティグループのインバウンドルールを削除しました。
最初の削除では、getCars Lambda 関数のセキュリティグループ(sg-049a4429b1733b7e6)が Aurora RDS クラスターのポート 3306 に接続することを許可していたルールが除去されました。
このルールがない状態では、Lambda からデータベースへのすべての接続試行がネットワーク層でブロックされ、結果として 約10秒のタイムアウト期間の後に TCP 接続タイムアウトエラーが発生します。
このネットワークレベルでのブロッキングにより、以下の現象が説明できます:
- Lambda のログに全呼び出しで 100%「connect ETIMEDOUT」エラーが記録される
- インシデント期間を通して、RDS のメトリクスにデータベース接続数が 0 と報告される
- Performance Insights が、Lambda が接続を試みているにもかかわらずデータベース負荷 0 を示す
- 各接続タイムアウトが Lambda の実行時間 10 秒超となって現れ、CloudWatch アラームをトリガーする
表示されている、「Go to root cause」のボタンをクリックします。
すると、次のような画面が表示されるので、「Generate mitigation plan」をクリックします。
(mitigation planは緩和策の作成となります)
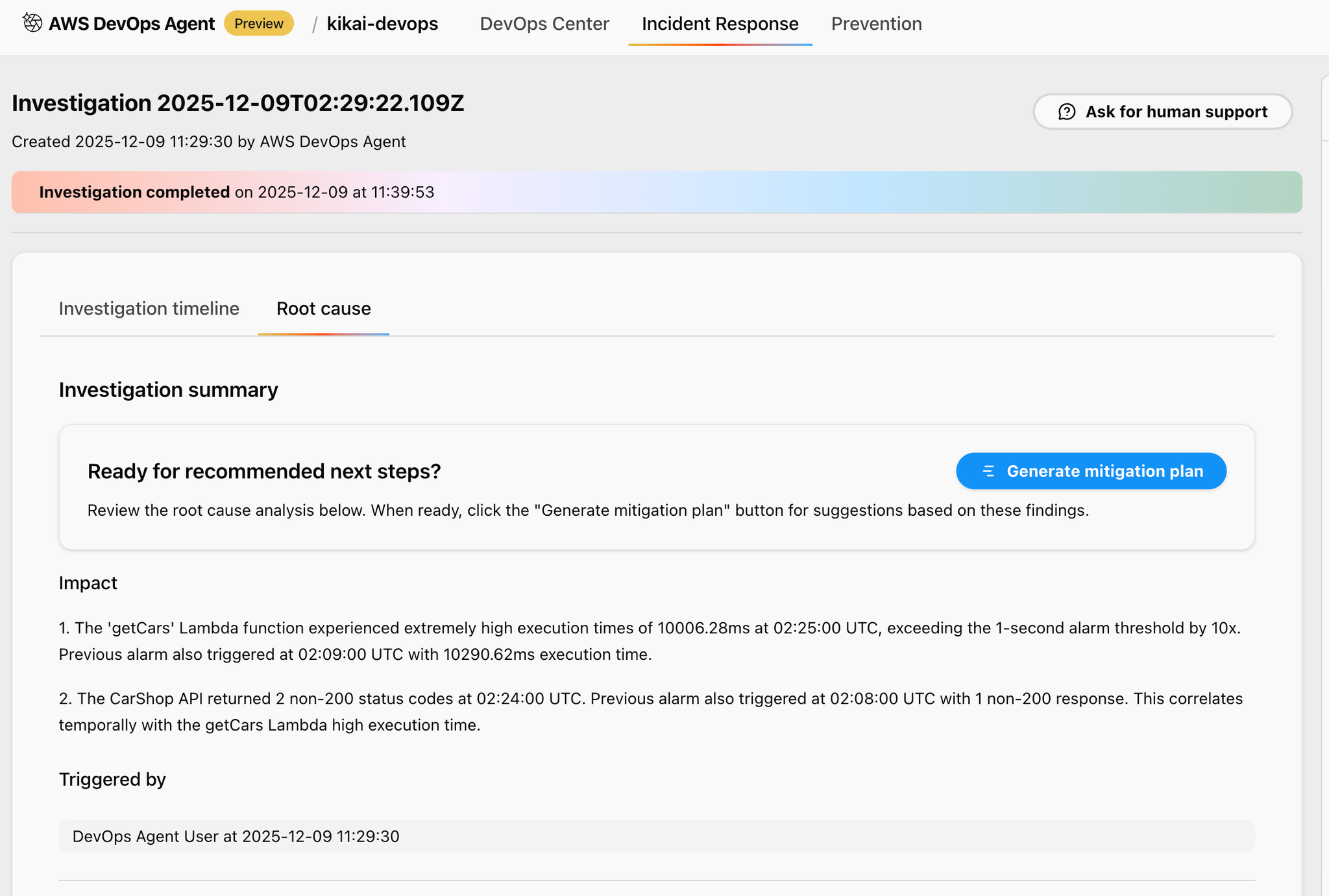
ここでも完了まで数分待ちましょう。
緩和策の計画が完了すると、以下のようにStepごとに提案がされます。
Step1は準備で、現在の状況を確認するAWS CLIコマンドが提案されています。
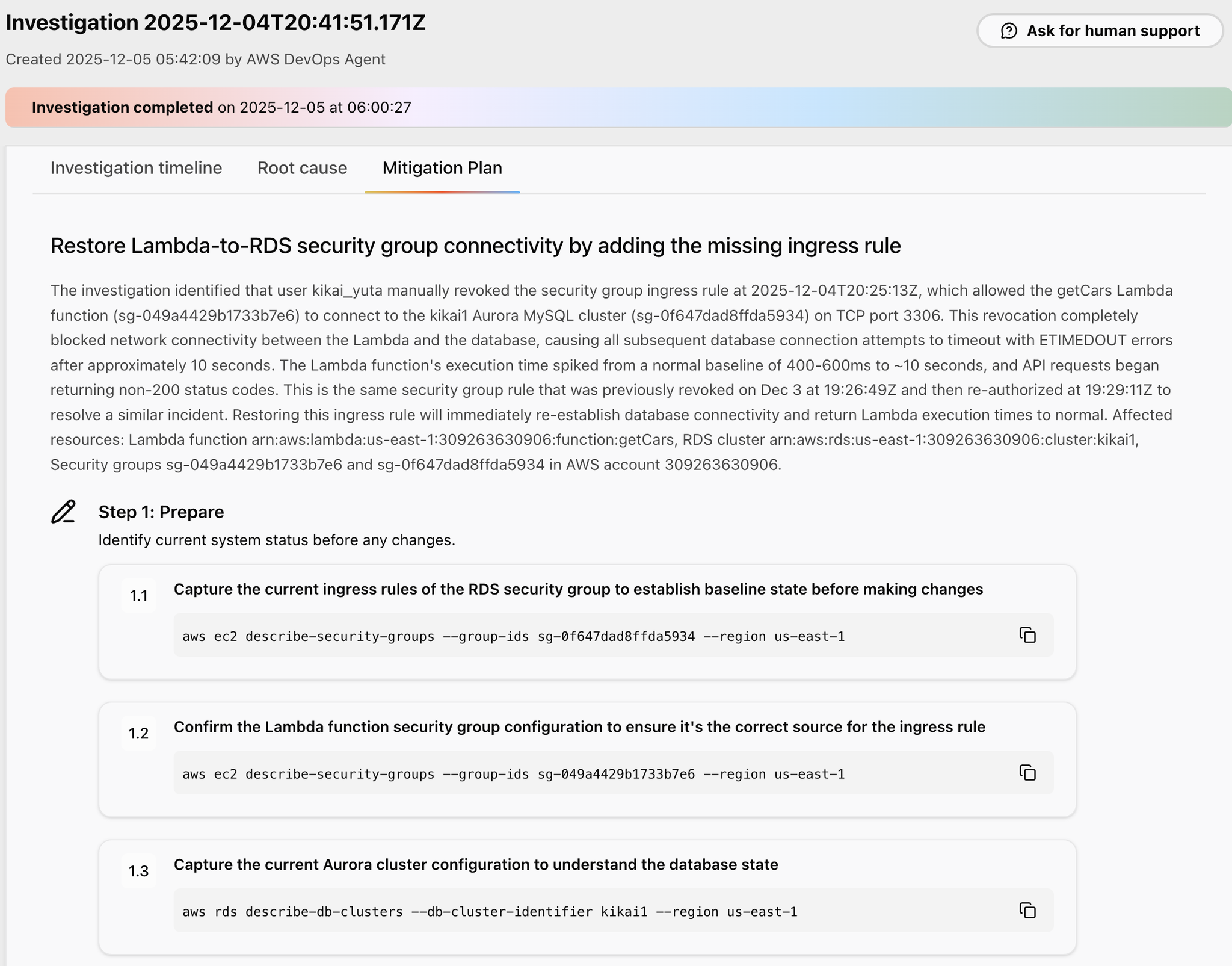
つづいて、Step2では事前検証として、現在も障害が続いているかや、Auroraクラスタが稼働しているかを確認するAWS CLIコマンドが提案されています。
Step3で修正を適用するAWS CLIコマンドが提案されています。
セキュリティグループの設定を変更するコマンドです。
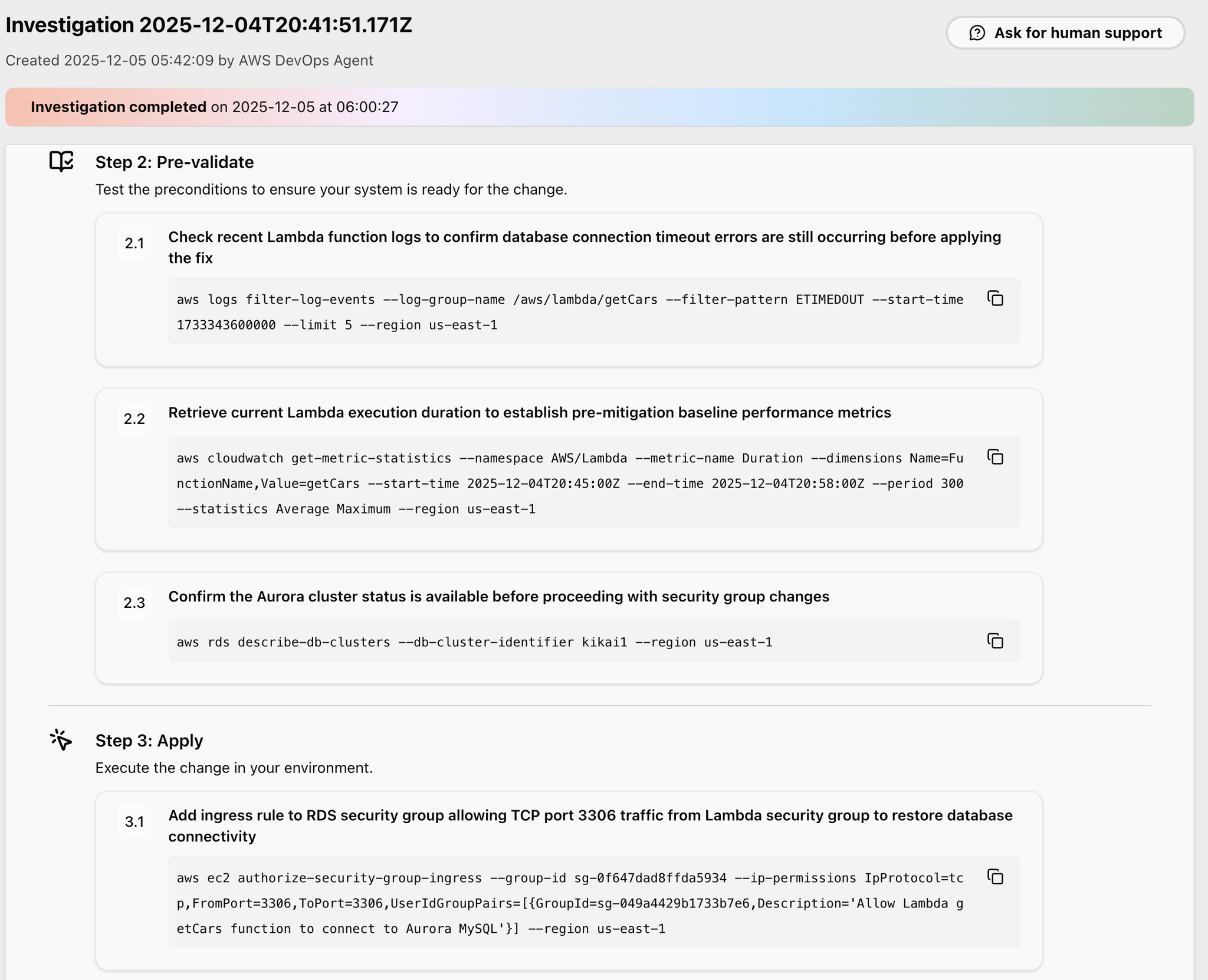
Step4では事後検証して、復旧したのかを調査するAWS CLIコマンドが提案されています。
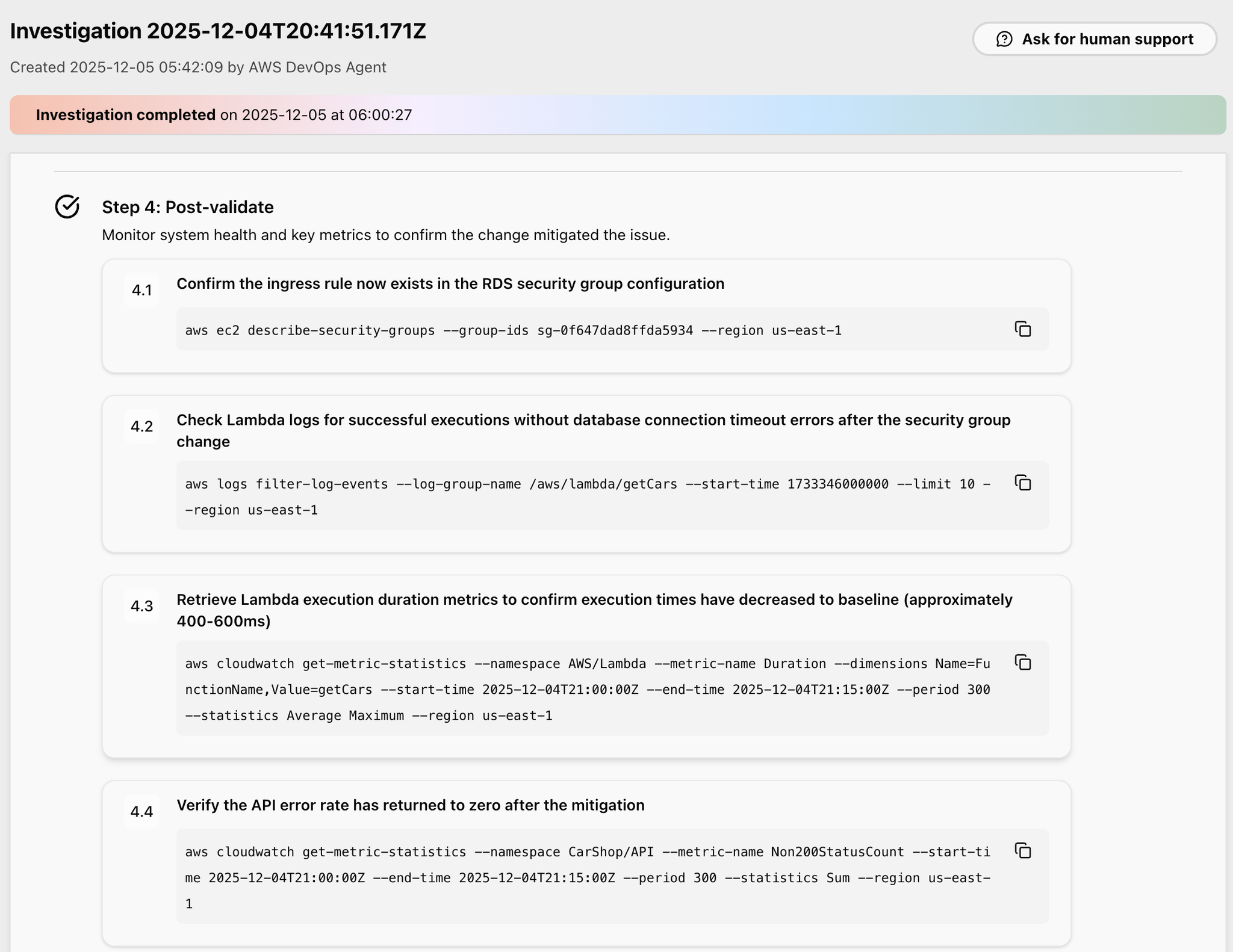
最後にRollbackの提案です。
復旧提案の操作で修正したセキュリティグループを、再度元の状態に戻すコマンドが提案されています。
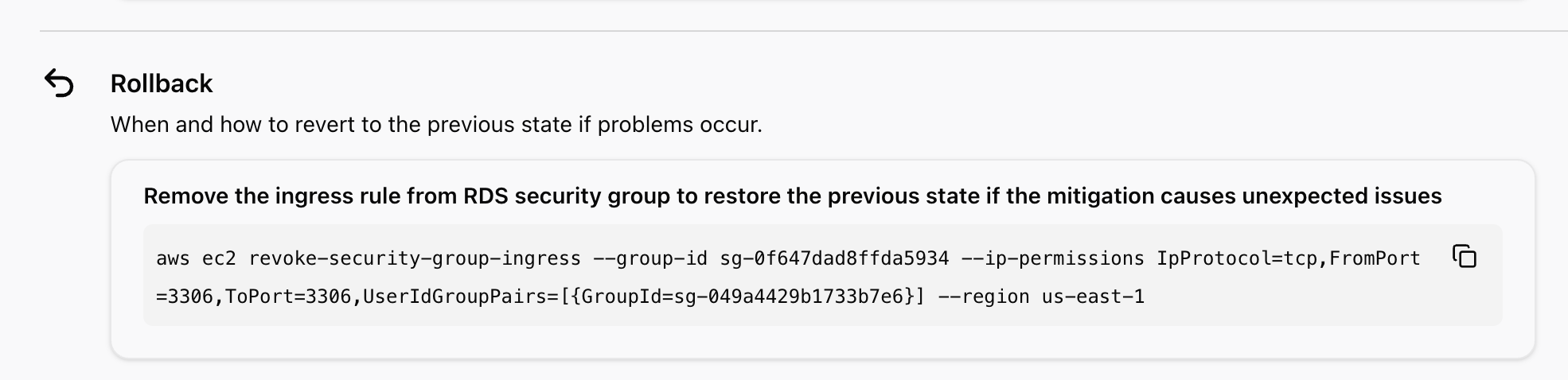
基本的にはStep1からStep4まで実行すればOKです。
では、Step3で提案された復旧コマンドを試してみます。
そして、Step4で提案されたコマンドを実行して、結果を確認しましょう。
Webシステムにも再度アクセスしてみると、無事に表示が復活しました。
最後に、DevOps AgentのPrevention(予防)タブを開いて、Runをクリックします。
すると、インシデントの防止有効な手段がないか調査を開始します。
完了すると以下のような画面になります
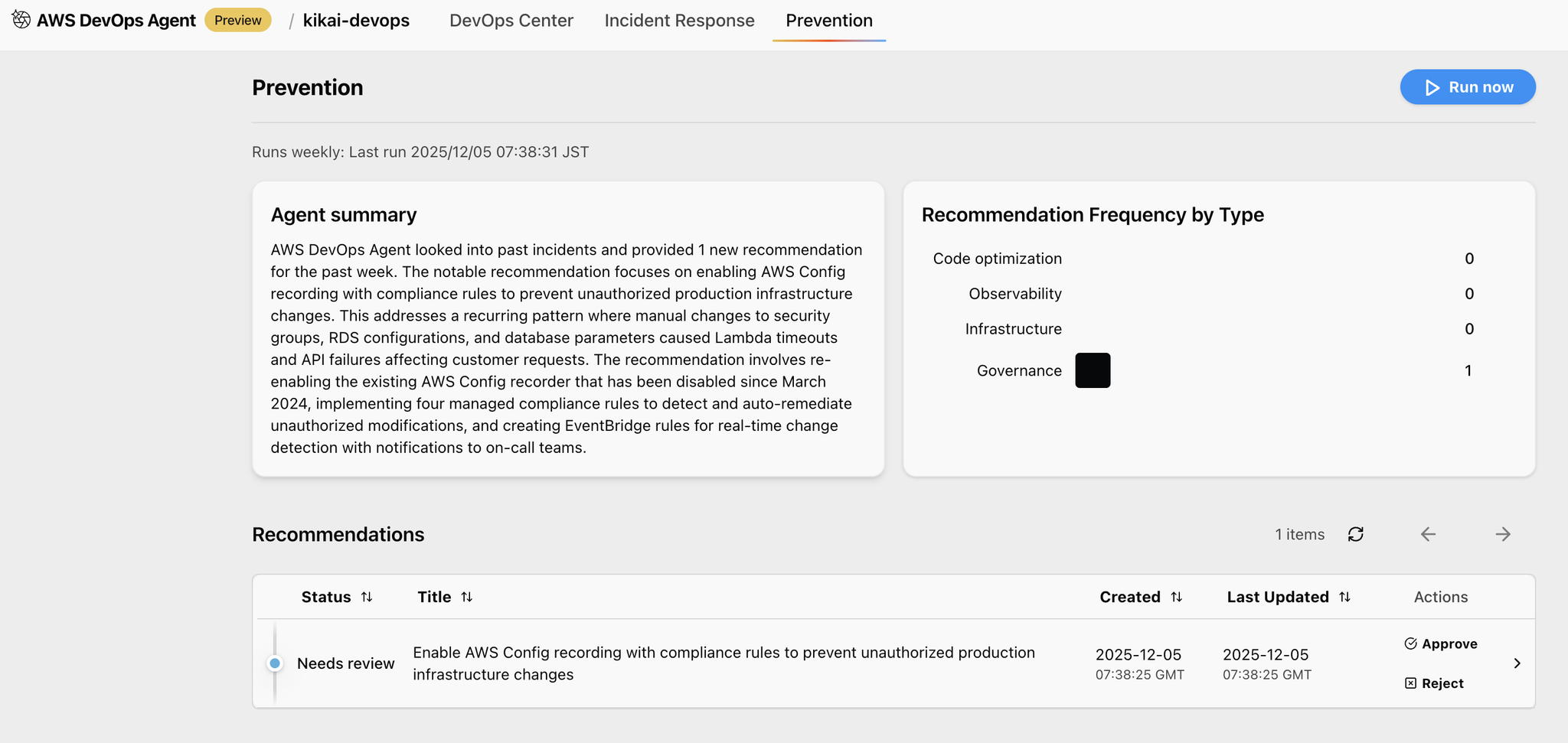
Recommendationsを開くとこうなる、予防策のレポートが表示されます。同じ障害発生を防ぐにはどうしたらいいかの提案がされています。

以上が、簡単なDevOps Agentの動作確認の内容となります。
今回の内容では触れていませんが、Runbookの機能もあります。
DevOps AgentのAgent Spaceを開いて、右上の歯車マークをクリックすると設定可能です。
Runbookの利用方法として、サービス特有の情報をMarkdownで記載しておくことで、DevOps Agentの調査を効果的に実行することが可能となります。
Runbookに記載する情報例:
DevOps Agentの現状の注意点
1. DevOps Agentのスコープは障害の根本原因調査・復旧策の提案・予防策の提案までで、復旧や予防策のコマンド実行はスコープ外
DevOps Agentは復旧コマンドの実行はスコープ外となります。
どうしても自動復旧をさせたい場合は、独自にAIエージェントを実装するなどして、DevOps Agentが提案した復旧案の内容を連携させる必要があります
2. プレビュー期間中の利用料金は無料だが制限がある
プレビュー期間中のDevOps Agentの利用料金は無料ですが、以下の制限があります。
- アカウントごとのAgent space 10個
- 月ごとのインシデント対応時間 20時間
- 月ごとのインシデント防止時間 10時間
- 月ごとのチャット メッセージ 1,000件
3. 初期状態だと障害調査の指示をDevOps AgentのUI画面から出さないと調査してくれない
CloudWatchアラームが発報しても、初期状態では自動で調査はしてくれません。
障害調査開始には大きくわけて3つの手段があります。
A. Built-in integrations
ServiceNow などのチケットシステムと連携し、チケットから自動でインシデント調査を開始
B. WebSockets/Webhooks
AWS DevOps Agent WebSockets 経由でイベントを送り、DatadogやDynatraceのアラームから自動トリガー
C. Manually
DevOps Agent Space の Web UI から手動で開始
初期状態では、のStart Investigationの文章入力欄から指示を出す必要があります。
自動で調査開始するには、DatadogやDynatrace、New Relicと連携を設定しアラートを受け取るようにする必要があります。
4. モニタリングサービス側対応状況の違い
上記のモニタリングサービスとの連携でもサービスごとに状況の違いがあります。
Dynatrace
Dynatraceのアカウント連携だけで設定可能
これはAWS側がDynatraceのMCPサーバーをDevOps Agent用にホスティングしてくれている為。
Datadog
Datadog側のRemote MCPサーバーの利用が必要。ただし、現時点でもリクエストによるプライベートプレビュー状態で、限られた顧客しか利用できない状態です。
New Relic
New Relic側のRemote MCPサーバーの利用が必要。パブリックプレビューなので、一般ユーザーでも利用可能な状態です。
Splunk
Splunk側のRemote MCPサーバーの利用が必要。
CloudWatch
CloudWatch単体でDevOps Agentの障害調査をトリガーすることは現時点でできません。
CloudWatchのアラームをトリガーとして、EventBridge/Lambdaなどを経由してDevOps AgentにWebhookでつなぎこみをする必要があります。
5. EC2サーバーの中までは調査できない
DevOps AgentはCloudWatchのログやメトリクス、各コンポーネントのステータスなどは調査できますが、EC2サーバーの中にあるログやプロセスの状態を直接確認することはできません。
仮に、EC2サーバーの中にApache,Tomcat,MySQLを同居させている状況で、MySQLが負荷が高騰しているとします。
DevOps AgentはEC2サーバーのCPU負荷が高騰しているということまではわかりますが、その原因が何なのかを知ることはできません。
適切にEC2サーバーの負荷状況を知らせるには、Datadogなど外部に詳細なメトリクスを送信して、それ経由でDevOps Agentに調査して貰う必要があります。
終わりに
DevOps Agentを使うことで障害の原因調査と復旧手順の提案の自動化を実現することができます。非常に期待できるプロダクトでした!
現在まだプレビューリリースですので、積極的に触ってフィードバックをAWSに送っていきましょう!
SRGにご興味ありましたらぜひこちらからご連絡ください。