
Google CloudにおけるカオスエンジニアリングBest Practiceを考える - 障害注入の実践編
メディア統括本部 サービスリライアビリティグループ(SRG)の小原です。
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
本記事は、Google Cloudにおけるカオスエンジニアリングについて、Chaos ToolkitとLitmusChaosを使った障害注入の実践方法を紹介します。
はじめにChaos Toolkitの障害実験LitmusChaosの障害実験環境準備ChaosToolkit - 実践ChaosToolkit - 課題課題1 設定値の動的な取得方法課題2 ロードバランサ構成要素の動的取得LitmusChaos - 実行環境の準備LitmusChaos - 実践LitmusChaos - 課題課題1 複数の実験タイプの管理課題2 ワークフローの実行やパラメータの渡し方終わりに
はじめに
Chaos ToolkitとLitmusChaosを使ったカオスエンジニアリングについて紹介します。
はじめに、それぞれのツールで利用する障害実験(experiment)の種類について説明します。
Chaos Toolkitの障害実験
ロードバランサへの障害注入を行います。障害テスト実行時にパラメータを指定して影響範囲の特定ができるようにすると良いでしょう。
| 障害タイプ | 障害の概要 | 影響範囲を制限するための考慮 |
| inject_traffic_delay | レイテンシー悪化 | FQDN, Path |
| inject_traffic_faults | エラー率悪化 | FQDN, Path |
LitmusChaosの障害実験
GKEへの障害注入を行います。影響範囲については、Pod障害ならNamespace, Labelなどを指定できると良いでしょう。また、NW障害については追加でIPやホストの指定ができるのでパラメータとして利用します。
| 障害タイプ | 障害の概要 | 影響範囲を制限するための考慮 |
| pod-delete | Pod削除 | NS, Label |
| pod-cpu-hog | Pod CPU負荷 | NS, Label |
| pod-memory-hog | Pod Memory負荷 | NS, Label |
| pod-network-latency | Pod NW レイテンシー悪化 | NS, Label, 宛先IP, Host |
| pod-network-loss | Pod NW エラー率悪化 | NS, Label, 宛先IP, Host |
| node-restart | GKE Node再起動 | AZ, Label |
| node-cpu-hog | GKE Node CPU負荷 | AZ, Label |
| node-memory-hog | GKE Node Memory負荷 | AZ, Label |
環境準備
今回使う以下のツールをセットアップしておきましょう。
- gcloud
- helm
- argo cli
- Python
- chaostoolkit
- chaostoolkit-google-cloud-platform
ChaosToolkit - 実践
Experimentの定義はJSONで管理します。
LBのエラー率悪化障害テスト用のサンプルを以下に示します。このexperimentはLBのURL MapリソースのRoute rules定義を書き換えます。Configurationで設定値を定義したり、環境変数から取得できます。以降で詳細を説明しますが、動的に値を取得して設定値とすることも可能です。
重要な構成要素は3つ(4つ)です。
- configuration
- 設定値を変数として定義
- method
- 障害注入の実行部分の定義(複数指定可能)
- rollbacks
- 障害注入の実行時間経過後に元の状態に戻すための定義(複数指定可能)
- steady-state-hypothesis
- ターゲットが正常に機能していることを確認するための定義
- オプション
このExperimentを実行します (uvでパッケージ管理しているのでuv経由で実行してます。)
でExperimentの定義ファイルのデフォルト値を上書きすることもできます。
実行ログは標準出力に出ますが にも記録されます。デバッグやエラー調査、処理の進捗を確認できます。
レイテンシー悪化のExerimentもほぼ同じように定義することで実現できます。
ChaosToolkit - 課題
実験の実装にあたって発生した課題と解決方法について紹介します。
課題1 設定値の動的な取得方法
定義ファイルへの動的な値を設定する方法について、テンプレートエンジンを利用すればChaosToolkit外での処理と組み合わせて変数展開できると考えつつも、JSONの視認性をあまり損わないようにしたく、Chaos Toolkit自体の機能による動的取得方法を模索しました。
そこで、ChaosToolkitの 変数置換 という機能を利用しました。
定義箇所を抜粋します。
Configurationで や といったProbeを定義することで、実験実行時に動的に設定値を取得するようになります。
これにより、実験設定を環境に応じて自動的に構成することが可能になり、環境ごとの設定ファイルを複数管理する手間を削減できました。
課題2 ロードバランサ構成要素の動的取得
ロードバランサに対して障害注入実験を行う際、対象となるURLマップ名やPath matcher名を実験定義に記述する必要がありました。
これらの名前はGoogle Cloudによる自動生成リソース名であったりするため、手動での特定は手間がかかります。また、ヒューマンエラーの原因にもなります。
この課題を解決するため、ドメイン名から関連リソースを全自動で取得するPythonスクリプト を用意しました。
先ほどの課題1で抜粋した定義ファイルの中に、スクリプトを実行するための設定が含まれています。
スクリプトで以下のように処理することで、必要な情報を動的に取得します。
- 入力されたドメイン名からIPアドレスをDNS解決
- 取得したIPアドレスからFrontendと紐付く情報を取得
- 情報を解析し、必要なURL mapリソースを取得
- URL map名とPath matcher名を取得
これにより、障害テストの実行時はドメイン名を指定するだけで複雑なリソース名を意識しなくてよくなります。
LitmusChaos - 実行環境の準備
実践の前に、ツール選定編でも少し触れたLitmusChaosの実行環境について説明します。LitmusにはControl PlaneとExecution Planeの2種類あります。厳密にいうと、最終的な実行環境としてはExecution Planeだけあれば動作しますが、全体的に構築しながら説明します。
helmを使ってControl Planeをデプロイします。
必要最低限のコンポーネントだけデプロイするのでvalues.yamlでパラメータを調整します。
values.yaml
frontendがWebUIのコンポーネントです。
設定したユーザ/パスワードでfrontendにアクセスし、以下のドキュメントの通りにExecution Planeをデプロイします。
マニフェストをダウンロードしてkubectl applyしてください。
これでLitmusの実行環境を構築しました。
LitmusChaos - 実践
ここから実際に障害を注入するための仕組みについて説明しながら実践していきます。
以下のシーケンス図から、Chaos Workflow カスタムリソースのデプロイをトリガーにして障害注入の処理が行われることがわかります。
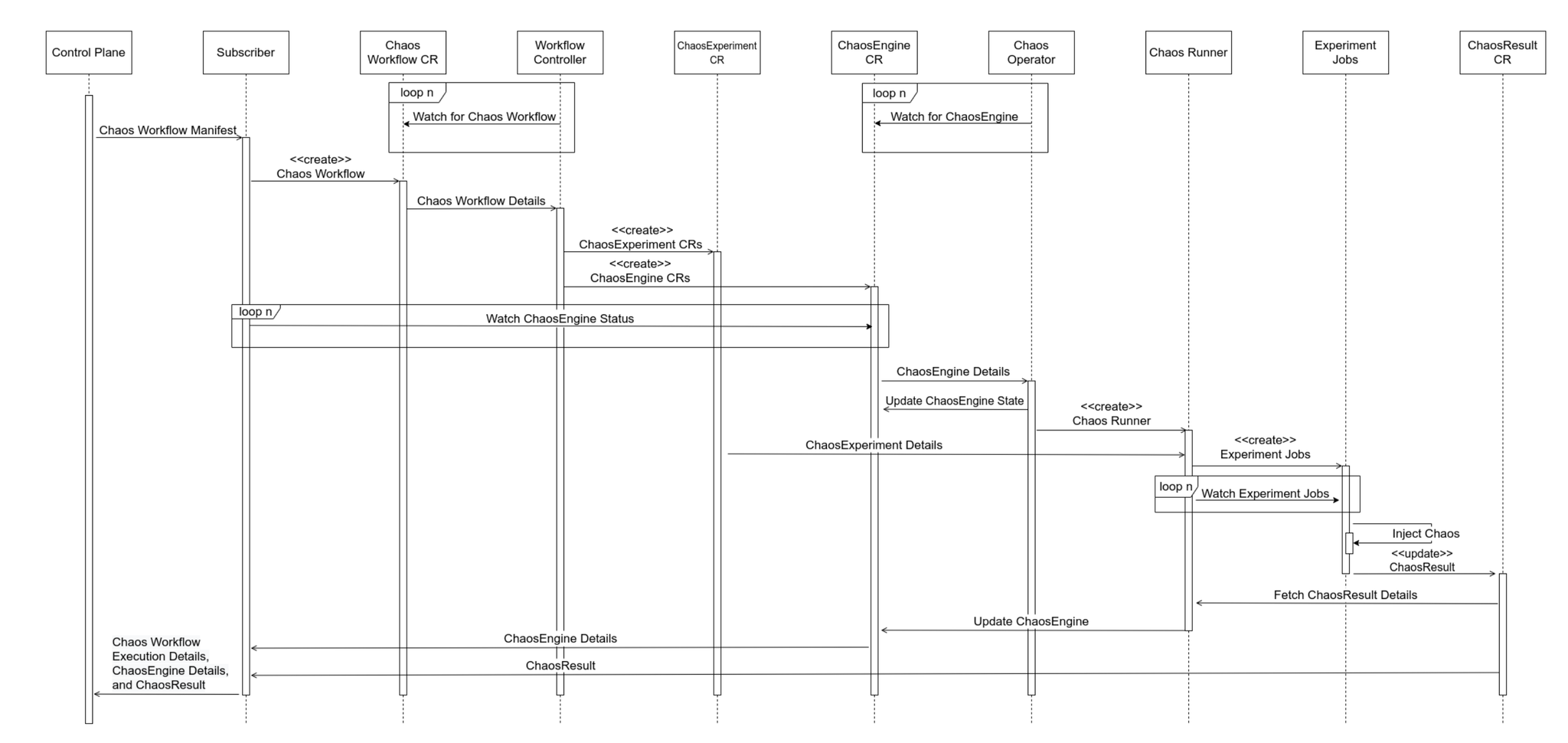
ワークフローはArgo Workflow形式で記述し、2種類のカスタムリソースを定義・適用する流れになっています。
- Chaos Workflow CR
- ChaosExperiment CR
- ChaosEngine CR
サンプルワークフロー pod-delete
WebUIからAdd Experiment > pod-deleteのテンプレートを選択し、作成しただけのワークフローです。作成後にマニフェストをダウンロードしましょう。
試しに上記のワークフローを実行します。今回、出番のないchaos-exporterを削除する障害テストをやってみます。ちなみにこのワークフローはLitmus実行環境固有のIDを保持していて、このままコピペしても他の環境では動きません。自分自身の環境で作成したワークフローを適用してください。
workflowを適用すると、3つのカスタムリソースが作成され、複数のPodが実行されたのがわかります。なんらかの原因でうまく動作していない場合はこれらのリソースの状況を確認します。
ChaosResult カスタムリソースを確認して が になっていれば無事テスト終了です。
応用編です。
冒頭でLitmusChaosで実施する障害テスト項目を紹介しましたが、これらの障害を注入するワークフローを実装します。私は1つのワークフローで実装しました。ワークフローをファイル分割すると同じような処理を繰り返し記述してしまう可能性があるので、1つにまとめています。yamlを貼ると膨大なのでフロー図で説明するとこんな感じです。
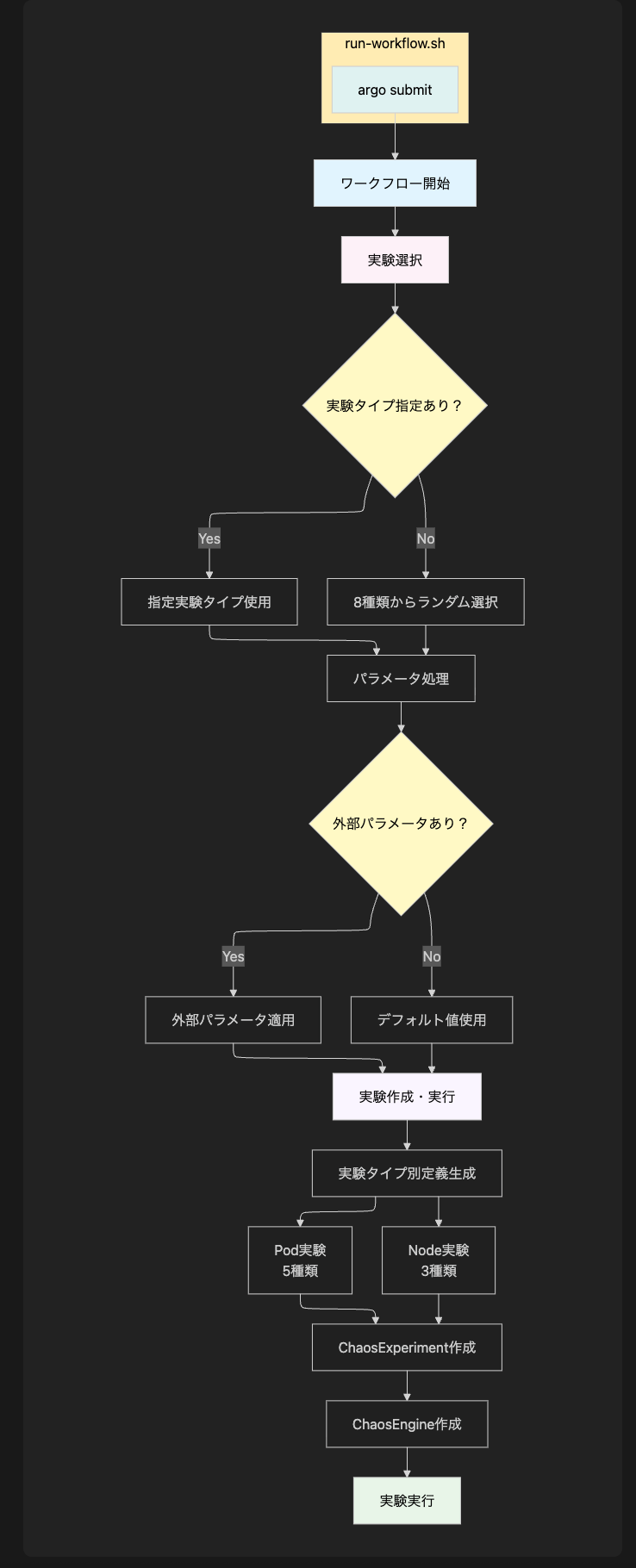
ラッバースクリプト(run-workflow.sh)経由で実行することで、必須の引数やデフォルト値の指定など、パラメータチェック処理をしたり、argo cli(argo submit)でworkflowにパラメータを展開したり でワークフローの完了まで待機できるようになっていて、柔軟に障害テストを実施できるようにしました。
LitmusChaos - 課題
課題1 複数の実験タイプの管理
Pod、Nodeを対象とする8種類の実験はそれぞれ必要なパラメータが異なります。手動での管理は非常に複雑であり、さらに実行時のヒューマンエラーのリスクがあります。 スクリプトを作成することで、実験の種類に関わらず単一のコマンドで全ての実験を統一的に実行できるようにしました。特に本番環境で実験を行う場合、影響範囲を厳密に制御し、安全性を確保することが重要です。
課題2 ワークフローの実行やパラメータの渡し方
もともとスクリプト経由のワークフロー実施は、内部でsedコマンドでのワークフローへのパラメータの置換処理や、kubectl applyによるデプロイ、ワークフロー実行中の待機処理を実装していてかなり非効率でした。
- テンプレートファイル書き換え→kubectl apply→実行完了待機→手動結果確認の複雑なフロー
- YAMLフォーマットを意識していないので文字列置換エラーのリスク
- 同時実行時のテンプレートファイル競合問題
などいろいろ問題だったのでargo cliによるワークフロー制御に変更しました。おかげでスクリプトやワークフローの記述がかなりシンプルになりました。
終わりに
本記事では、ChaosToolkitとLitmusChaosという2つのツールを用いたカオスエンジニアリングの実践事例と、その過程で直面した課題への具体的な解決策を紹介しました。
ツールを導入するだけでなく、運用上の課題に対してスクリプト開発、パラメータの工夫、設定管理の見直しといった改善を積み重ねることで、ヒューマンエラーを減らし、より安全で再現性の高いカオスエンジニアリングの実践が可能になります。
ChaosToolkitは宣言的な記述による柔軟な実験定義に、LitmusChaosはKubernetesネイティブな連携と豊富な実験セットに強みがあります。
これらの事例が、これからカオスエンジニアリングに取り組み、システムの信頼性向上を目指す方々の一助となれば幸いです。
SRGにご興味ありましたらぜひこちらからご連絡ください。