
どのValkeyマネージドサービスを選ぶ? AWS (ElastiCache/MemoryDB) vs Google Cloud (Memorystore)
メディア統括本部 サービスリライアビリティグループ(SRG)の小林(@berlinbytes)です。
#SRG(Service Reliability Group)は、主に弊社メディアサービスのインフラ周りを横断的にサポートしており、既存サービスの改善や新規立ち上げ、OSS貢献などを行っているグループです。
本記事は、Valkeyマネージドサービスの違いについて、特徴と使い分けをベンチマークから検証してみる記事になります。
はじめに
弊社では、プライベートクラウドを含め複数のパブリッククラウド上でもサービスを展開しています。
新規サービス開発において、メインの基盤となるプラットフォームを選定する際に、そのプラットフォームでしか実現できない機能がある場合は決めやすいと思います。
しかし最近では欲しい機能は各社揃ってきています。
こういった状況において、次に重要になってくるのはコストと性能の兼ね合いになってきます。
今回は、2024年に商用利用に制限が設けられたことによりRedisからフォークされた、Valkeyについてプラットフォームとサービスの違いによる差異を検証してみようと思います。
Valkeyについての比較としては、マネージドのサービスである
- Amazon ElastiCache for Valkey
- Amazon MemoryDB for Valkey
- Google Cloud Memorystore for Valkey
を対象としてみたいと思います。
AWSにおいては、他のデータベースの前段に置くキャッシュ用途に最適化されているElastiCacheに加え、単一のプライマリデータベースとしても使用可能な可用性と永続化が強化されているMemoryDBがあり、双方においてValkeyエンジンが使用できますが、ElastiCacheでは7.2/8.0、MemoryDBでは7.2/7.3という使用できるバージョンの違いがあるようです。(2025年4月現在)
Google Cloudではシャード数、レプリカ数とティアを調整するというオプションによって、AWSと同等の機能をMemorystoreサービス1つで実現させているイメージです。
こちらもValkeyエンジン(7.2/8.0)が使用できます。
また、今回はせっかくなので最新のArmインスタンスから負荷をかけることにして、それらのベンチマークも簡単に比較してみたいと思います。
負荷試験準備
負荷をかける側のインスタンス
最近ではAWSにおいてはコスト効果の高い、ArmベースのGravitonプロセッサの利用が一般的になってきました。
現在では最新のGraviton 4プロセッサが、8g世代として提供されています。
またGoogle Cloudでも、ArmベースのAxionプロセッサで提供される、C4Aマシンタイプのインスタンスが、2024年10月からGAされています。
Google Cloud側では、東京リージョンでも2025年3月末くらいからつかえるようになっているAxionプロセッサを使用してみたいと思います。
そしてAWS側はこのAxionと同じ、Arm Neoverse-V2設計に基づいているGraviton 4プロセッサを使ってみることにしましょう。
インスタンスサイズ/マシンタイプはAWSとGoogle Cloudで共に揃っており、vCPU 対メモリ比でシリーズが決まっています。
簡単に表にすると、このようになります。
| vCPU : Memory | AWS | Google Cloud |
| 1 : 2 | Compute Optimized c8g | highcpu c4a-highcpu |
| 1 : 4 | General Purpose m8g | standard c4a-standard |
| 1 : 8 | Memory Optimized r8g | highmem c4a-highmem |
今回はバランスの取れた1 : 4、vCPUは2coreのものを使用したいと思います。
| プロバイダー | AWS | Google Cloud |
| インスタンスタイプ | m8g.large | c4a-standard-2 |
| CPU Core数 | 2core | 2core |
| メモリ | 8.0 GiB | 8.0 GB |
負荷をかけられる側のValkey
AWS側においては8g世代のノードタイプを選択できるリージョンがまだ無く、またGoogle Cloud側においてもノードタイプのCPU世代は公開されていない様子だったので、双方ともに同じvCPU数とメモリ量でスペックを合わせることにして、比較を行うことにします。
今回は、vCPU2coreに対してメモリが13 GBのもので比較します。
Valkeyのバージョンは、ElastiCache7.2/8.0、MemoryDBでは7.2、MemoryStoreでは7.2/8.0で比較をしてみようと思います。
MemoryDBでも8.0が選べるようになったら、また検証してみたいですね。
まとめると、以下のようになります。
| プロバイダー | AWS | AWS | Google Cloud |
| サービス | ElastiCache for Valkey | MemoryDB for Valkey | Memorystore for Valkey |
| インスタンスタイプ | cache.r7g.large | db.r7g.large | highmem-medium |
| CPU Core数 | 2core | 2core | 2vCPU |
| メモリ | 13.07 GiB | 13.07 GiB | 13 GB |
| リージョン/ゾーン | シングルリージョン | シングルリージョン | シングルゾーン |
| シャード数 | 1 | 1 | 1 |
| レプリカ | なし | なし | なし |
| エンジン | Valkey 7.2 / 8.0 | Valkey 7.2 | Valkey 7.2 / 8.0 |
テスト方法
- まずは負荷をかけるインスタンス側の処理能力をざっくり知るため、CoreMarkスコアを測定します。CoreMarkはCPU単体の性能評価の指標としてよく使われおり、こちらで様々なCPUスコアが公開されています。
CoreMarkのパラメーター
- 次に、マネージドのValkeyインスタンスにデータを30-40%程度詰め込みます。これは、空っぽの状態で運用しているサービスは少ないのと、データが何もない状態からベンチを走らせると良い結果になりがちだったため、実際の運用に即したベンチ結果を出すためです。
- 続いて各パブリッククラウド内で、同一リージョン同一ゾーン上の負荷をかけるインスタンスからmemtier_benchmarkにてベンチマークを実施します。
- 3種類のワークロード(Write Only / Read Only / Read:Write=1:1)のベンチマークを各3分間、5セットの負荷をかけます。
memtier_benchmarkのパラメーター
書き込み
読み取り
読み書き混合
- 各5セット平均の、1秒あたりの操作数とP99レイテンシを比較していきます。
負荷試験結果
インスタンス
| プロバイダー | AWS | Google Cloud |
| インスタンスタイプ | m8g.large | c4a-standard-2 |
| CPU | AWS Graviton4 Processor | Google Axion Processor |
| Arm IP | Arm Neoverse-V2 | Arm Neoverse-V2 |
| OS | Ubuntu 24.04.2 LTS | Ubuntu 24.04.2 LTS |
| Coremark スコア | 57405 | 61439 |
Graviton4は、性能価格比で評価の高いGravitonシリーズでも1番高いスコアが出ているようです。
Axionに関しては、同じ第4世代のIntelプロセッサのインスタンスと比較すると、4割以上の性能向上がありそうです。
両者のオンデマンド価格に差はほとんどありませんが、Axionの方が7%ほど高い性能がでていますね。
こちらは両者共に公式に明言はされていないようですが、いくつかのサイトで報告されているようなクロック周波数の差異の範囲内のものだと思われます。
(Graviton4 2.7-2.8GHz、Axion 3.0GHz?)
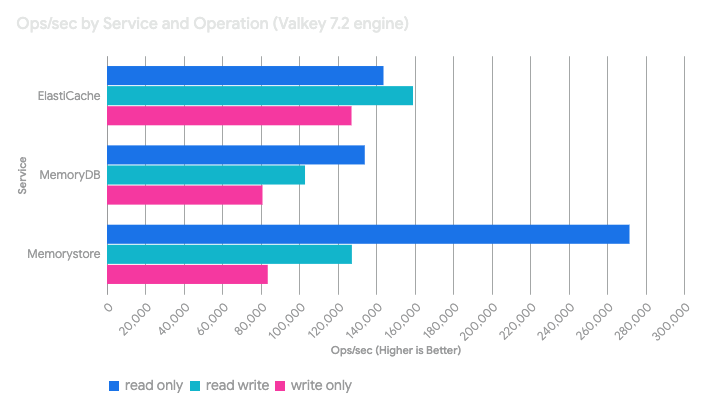
Valkey 7.2
3種類のワークロード(Write Only / Read Only / Read:Write=1:1)に対する、まずはValkey7.2エンジンでの結果です。

Valkey8.0
そして、こちらがValkey8.0エンジンでの結果です。


考察
まずValkey 7.2エンジンでの比較において、Memorystoreが他のサービスと比較して、突出した読み取りの性能を示しました。
しかし書き込みは同様の傾向ではなく、Memorystoreが書き込みや読み書き混合パターンより、読み取り操作を優先にチューニングをしている事を示唆していそうです。極端な読み取りヘビーなキャッシングが想定されるサービスに最適ですね。
そして、ElastiCacheにおいては全てのパターンにおいて良好で、特に読み書き混合パターンにおいての性能とp99レイテンシが優れていました。
これは最もバランスが取れていると表現できそうです。
この性能は汎用性が高く、読み取りと書き込みの両方が発生するセッション管理、頻繁にアクセスされるデータのキャッシングといった、キャッシングレイヤーというそもそもの設計目標を反映していそうです。
一方で、MemoryDBでは双方と比較すると、読み書き性能とレイテンシにおいて劣っているように見えます。しかしこれはそもそもの設計思想が反映されているためだと思います。
MemoryDBは、ElastiCacheやMemorystoreのようなキャッシュではなく、耐久性のあるプライマリデータベースという異なるカテゴリにあるためだと考えられます。
他サービスにはない、Multi-AZトランザクションログで耐久性を実現しており、独立したキャッシュ+データベースレイヤーの必要性をなくすという、想定されたトレードオフのようです。
Valkey 8.0エンジンでの比較においては、ElastiCacheでは書き込み性能がわずかにあがったものの、性能向上は確認することができませんでした。
MemorystoreではすべてのワークロードでOps/secが5%程度増加しており、P99レイテンシも改善されています。
読み取り操作を優先にチューニングされている傾向はそのままのようです。
したがって、エンジンバージョンのアップグレードが必ずしも単純な性能向上には結びつくわけではなさそうでした。
パフォーマンスへの影響を確認する際には、実際のワークフローと環境下においてのテストが不可欠かもしれません。
価格
さて、最後はコスト面です。
今回使用したノード単位でのコスト差異として、東京リージョンのオンデマンド価格で比較すると
MemoryDBは、ElastiCacheより約25%程度高くなっているようです。
MemoryStoreは、ElastiCacheより約17-20%高く、MemoryDBより5-11%安い計算になります。
| プロバイダー | AWS | AWS | Google Cloud |
| サービス | ElastiCache for Valkey | MemoryDB for Valkey | Memorystore for Valkey |
| インスタンスタイプ | cache.r7g.large | db.r7g.large | highmem-medium |
| オンデマンド価格(時間) | $0.2104 | $0.2597 | $0.247 |
| オンデマンド価格(月額) | $151.488 | $186.984 | $177.84 |
| リージョン/ゾーン | ap-northeast-1 | ap-northeast-1 | asia-northeast1 |
ElastiCacheではインスタンス料金に加えて、
- データ階層化を使用する場合はその価格
- ネットワーク料金 (AZやリージョンを跨いだ通信のみ)
- バックアップ料金 (バックアップを使用する場合)
MemoryDBではインスタンス料金に加えて、
- データ階層化を使用する場合はその価格
- 10TB/月以上の書き込みがある場合は、それ以上の書き込みに対して
- データ転送料金 (マルチリージョンを使用した場合)
- スナップショットストレージ価格 (スナップショットを使用する場合)
MemoryStoreではインスタンス料金に加えて、
- AOF persistence料金 (AOF永続化を行なっている場合)
- ネットワーク料金 (ゾーンやリージョンを跨いだ通信のみ)
- バックアップ料金 (バックアップを使用する場合)
がそれぞれかかります。
終わりに
Valkeyエンジンを持つマネージドサービスの比較は以上となりますが、結論を簡単にまとめると、
読み取りヘビーなキャッシングにはMemorystoreが最適なようです。
汎用的なキャッシング、セッションストア、そしてバランスの取れたワークロードには、ElastiCacheが向いていると思います。
データの耐久性と強力な一貫性が最優先される場合は、書き込みレイテンシとコストのトレードオフを許容した上でMemoryDBが最適解になるかと思います。
他パブリッククラウドでのValkeyマネージドサービス、そしてエンジンバージョンが上がった際にもまた比較検討してみたいです。
Redisエンジンとの比較については、私と同じSRGチームに所属する鬼海さんの記事に詳しいです。
Elasticacheでは、今回はオンデマンドノードでの検証でしたが、サーバレスという選択肢もあります。
サーバレスでの検証は、Applibot SREチームの中島さんの記事がよくまとまっています。
こちらも参考にしてみてください。
SRG では一緒に働く仲間を募集しています。
ご興味ありましたらぜひこちらからご連絡ください。